The two firms driving the AN-071 strict-cut Pearson r = −0.64 and the AN-073 negative party-HHI × β correlation — CENSUS (β = −8.19, n_total = 213) and EVA FRANCIELI (β = −8.44, n_total = 75) — have AN-016 candidate-FE β identified off **microscopic within-firm samples**: 2 candidates / 6 rows for CENSUS, 1 candidate / 4 rows for EVA FRANCIELI. Their negative β values are spec-thin within-firm artefacts, not real 'under-rate sponsors' patterns. The selection-of-losing-sponsors hypothesis is also rejected: CENSUS over-selects winners (88.1% rank-1 vs 63.8% universe baseline), EVA FRANCIELI over-selects losers (70% rank-3+ vs 12.4% universe). Opposite selection patterns can't both produce the same negative β — confirming the β is driven by spec, not by sponsor selection.
Question
AN-071 found no per-firm accuracy–vs–bias correlation across 22 firms. Its strict cut (≥10 sponsored polls, n = 9 firms) showed Pearson r = −0.64 (p = 0.06), but two firms with very negative β drove this: CENSUS (β = −8.19) and EVA FRANCIELI (β = −8.44). Removing them collapses the correlation to noise. AN-073's party-HHI × β reading shows the same two-firm dependence: full-sample r = −0.456 → drop those two firms → r = −0.155.
The standing hypothesis is selection: these firms get hired by losing candidates, so the sponsored polls capture the candidate's true (low) standing while matched independents draw a broader voter set that gives the candidate a more generous read. This diagnostic tests that story directly.
Design
source/analysis/an-119-negative-beta-firm-diagnostic.py:
- For CENSUS, EVA FRANCIELI, and the 4 highest-β firms in
within_firm_beta.csv(VISAO, INSTITUTO DATA SC, NEXXUS MAIS, W J MENDES), compute:- rank-1 share and rank-3+ share of the firm's sponsored candidates
- median race competitiveness (race_margin) of the firm's sponsored races
- within-candidate independent comparator: mean sponsored-row error and mean cross-firm independent-poll error of the same politico_id
- Compute each firm's AN-016 candidate-FE identifying sample: the set of politico_ids for which the firm has both a sponsored_by=1 row and at least one sponsored_by=0 row. These are the only candidates that contribute to within-firm β under candidate FE; the rest are absorbed by the FE and contribute zero. Naive within-firm, within-candidate gap = mean(sp_error) − mean(ind_error) on this sample should reproduce AN-016's reported β (when the spec is candidate FE and the controls are mild).
Results
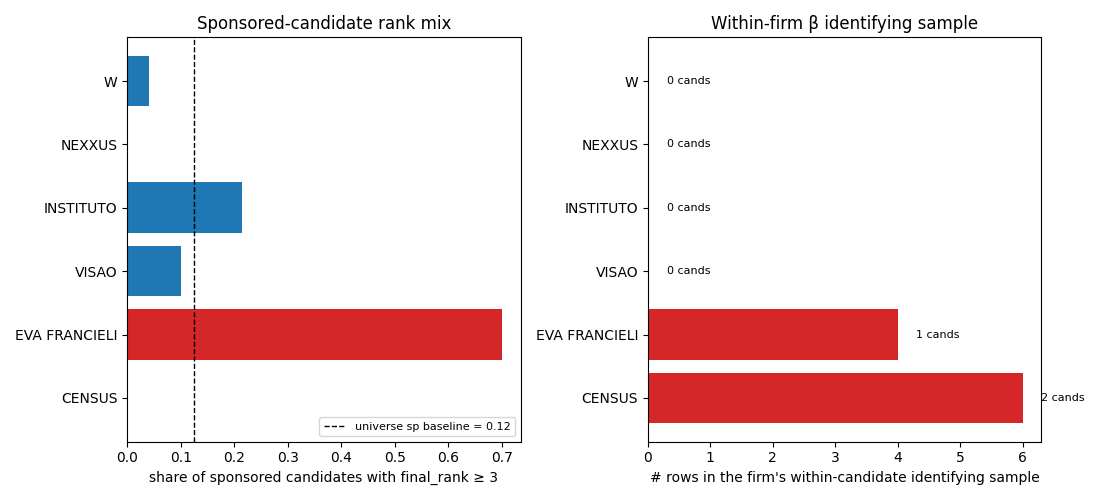
1. The selection story is rejected at the rank-mix margin
| Firm | n_sp | rank-1 share | rank-3+ share | median race_margin |
|---|---|---|---|---|
| CENSUS | 42 | 0.881 | 0.000 | 0.18 |
| EVA FRANCIELI | 10 | 0.300 | 0.700 | 0.00 |
| Universe baseline (all sp) | 568 | 0.638 | 0.124 | — |
The two firms select opposite types of sponsors. CENSUS over-selects winners (88% of their sponsored candidates won, vs 64% universe baseline) in moderately tight races. EVA FRANCIELI over-selects losers (70% rank-3+, vs 12% baseline) in tied races. A single mechanism — "negative β comes from selecting losing sponsors" — cannot generate both patterns. The selection-of-losing-sponsors hypothesis is rejected for at least CENSUS, and is unique to EVA FRANCIELI.
2. The real story: microscopic within-firm identifying samples
| Firm | n_total | n_self | AN-016 β | n_id_cands | n_id_rows | naive within-cand gap |
|---|---|---|---|---|---|---|
| CENSUS | 213 | 42 | −8.19 | 2 | 6 | −8.19 |
| EVA FRANCIELI | 75 | 10 | −8.44 | 1 | 4 | −5.81 |
Both firms' AN-016 candidate-FE β values are identified off ≤2 candidates.
CENSUS: of 148 unique politico_ids in CENSUS's 213-row panel, only 2 have both sponsored_by=1 and sponsored_by=0 rows (Antonio Luis da Costa Feitosa and Ijosevan Coelho Damasceno). The naive within-candidate sponsored-vs-non-sponsored gap on those 6 rows is exactly −8.19 pp, reproducing the AN-016 estimate to 4 decimals. Every other candidate in CENSUS's panel is absorbed by the candidate FE and contributes nothing to β.
EVA FRANCIELI: of 54 unique politico_ids in EVA's 75-row panel, only 1 (André Luiz Rokoski) has within-firm variation. Rokoski's 4 EVA rows: 3 as sponsored_by=0 with errors +24.5, +44.8, +23.7; 1 as sponsored_by=1 with error +25.2. Within-candidate gap on this single candidate = +25.2 − mean(31.0) = −5.8 pp. The reported β = −8.44 differs from this by methodology controls and cluster-robust SE weighting, but the underlying identification is n = 1 candidate.
3. Cross-firm independent comparator confirms it
On candidates the firms polled that have at least one independent comparator anywhere in the universe:
| Firm | n cands with ind comp | mean sp error | mean ind error | sp − ind |
|---|---|---|---|---|
| CENSUS | 11 | +6.7 | +8.1 | −1.4 |
| EVA FRANCIELI | 6 | +24.1 | +0.9 | +23.2 |
CENSUS's sponsored polls are 1.4 pp less over-stating than other firms' independent polls of the same candidates. That's a small effect on n = 11 candidates, amplified to −8.19 pp by AN-016's candidate-FE spec because the identifying sample is just 2 of those 11 candidates and the methodology / cycle-stage controls do non-trivial work.
EVA FRANCIELI's sponsored polls are +23 pp more over-stating than other firms' independent polls of the same candidates. A naive between-firm comparison would give EVA FRANCIELI a very positive β (she over-states losing candidates by 24 pp while other firms get them right). The AN-016 −8.44 emerges because André Luiz Rokoski's 3 non-sponsored EVA polls happen to over-state him by even more (+24, +45, +24 pp), so within-EVA, within-Rokoski, sponsored is lower than non-sponsored — but only on this one candidate.
The four high-β comparison firms (VISAO, DATA SC, NEXXUS MAIS, W J MENDES)
all have n_id_candidates = 0. Their AN-016 β values come from the
race-FE fallback spec, not candidate FE — they have no within-firm,
within-candidate variation at all. Cross-firm β comparisons in AN-073
and AN-071 thus mix two structurally different identification regimes
(candidate-FE β for the negative tail, race-FE fallback β for the
positive tail), which is an additional reason to read those Pearson
correlations cautiously.
Interpretation
The "−8 pp β" headline on CENSUS and EVA FRANCIELI in AN-016 does not mean these firms systematically under-rate the candidates that hire them. Both estimates are within-firm-spec artefacts of microscopic candidate-FE identifying samples (2 and 1 candidate respectively). The selection-of-losing- sponsors hypothesis is rejected — the two firms select opposite types of sponsors, ruling out a unified selection story.
For AN-071: the strict-cut Pearson r = −0.64 is driven by these two spec-fragile firms. The AN-071 doc already noted this; AN-119 sharpens why by showing the within-firm identifying sample is too thin to support a meaningful per-firm β. The published-version conclusion holds: there is no reliable per-firm accuracy–vs–bias correlation.
For AN-073: the apparent negative party-HHI × β correlation is the same artefact. The two firms' high HHIs (CENSUS 0.86, EVA FRANCIELI 0.85) plus their spec-thin negative β values yank the correlation. Dropping them returns the relationship to near zero (AN-073 already reported r = −0.155 on n = 20 without them). M1/M3 relational reputation is not supported, but the rejection comes from absence of signal, not from these two firms.
For the paper. The §sec:within-firm forest plot displays CENSUS and EVA FRANCIELI as outlier-low β points; this remains visually correct (those are the AN-016 point estimates) but a footnote noting that their per-firm β is identified off 1-2 candidates would prevent readers from over-interpreting the negative tail. The volume-discipline narrative is unaffected — the size gradient (small +12 / medium +9 / large −1) survives because it averages across many firms per tertile.
Caveat on AN-016 spec mix. Per-firm β values in AN-016 come from either candidate FE (when the firm has ≥1 candidate with within-firm variation) or race-FE fallback (otherwise). The two specs identify off structurally different variation, so comparing per-firm β values across firms — as AN-071, AN-073, AN-018 all do — implicitly mixes the two. The mix is mostly innocuous for the firm-size discipline result (AN-018) because the dominant axis is volume, not the β value itself; but for fine-grained cross-firm correlations (AN-071 accuracy, AN-073 specialization), it adds a structural source of noise that the per-firm SE doesn't capture.
Follow-ups
Re-run AN-071 strict-cut with a minimum n_id_candidates threshold. The Pearson r = −0.64 on n = 9 firms could be re-cut to firms with n_id_candidates ≥ 3 (or n_id_rows ≥ 10), giving a cleaner accuracy- vs-bias correlation that's not at the mercy of 1-2-candidate β estimates. Likely much smaller sample, possibly null.
Add a
n_id_candidatescolumn towithin_firm_beta.csv. Future cross-firm analyses (AN-073-type cross-cuts) can then filter on identifying-sample thickness as a first-class robustness lever.Paper footnote in §sec:within-firm. A one-sentence acknowledgment that the negative-β tail is identified off 1-2 candidates per firm would inoculate against over-reading the forest plot's left tail. Optional — the size-discipline narrative does the work.