Wild-cluster bootstrap on the race-week-FE-only spec (β=+4.68, n=448, G=51 muni clusters): WCR two-sided p = 0.0175 (B=2000 Rademacher draws); WCU 95% percentile CI [+1.09, +8.29] and percentile-t CI [+0.88, +8.50]. WLS spec-2 weighted by sample_size: β=+8.15 (SE 1.42, p<0.001) — within 0.18 pp of the unweighted baseline. Week-window sensitivity (`%U` baseline vs `%V` ISO vs 10-day vs 14-day rolling): β range [+4.16, +5.31], all p < 0.02 — the race-week-FE-only spec is not brittle to the week-boundary definition. The proper spec-3c TWFE wild-cluster bootstrap (candidate FE + race-week FE) is parked as a follow-up; the rejection here on the more conservative spec extends to the headline a fortiori.
Question
Three coordinated specification-level stress tests for the +7.94 spec-3c coefficient, picking up the loose ends from AN-010 / AN-011:
- Wild-cluster bootstrap. Spec 3c's cluster-robust SE relies on CRVE asymptotics with G = ~30–50 muni clusters. AN-010 K1 already showed the SE inflates fast under sample cuts. Wild-cluster bootstrap (Cameron, Gelbach & Miller 2008) is the standard correction at this cluster count. Both WCR (restricted, for p-value under H₀) and WCU (unrestricted, for percentile CI), B = 2000 Rademacher draws at muni level. The p-value and CI should mostly track CRVE but the comparison is paper-note value.
- WLS by sample size. Sponsors may systematically pay for
smaller-sample polls (cheaper to slant via small-sample noise).
Re-estimating spec 2 weighted by
QT_ENTREVISTADOtests whether the result survives when small polls receive less weight. - Week-window sensitivity. The race × week FE uses
strftime('%Y-W%U'), where%Uweeks start on Sunday. AN-010's red-team flagged that weeks crossing the election boundary inconsistently. Re-run spec 3c with:%VISO weeks (Monday start, ISO-8601), 10-day rolling cells, and 14-day rolling cells. β should be stable across the four definitions.
Design
source/analysis/an-012-spec-se-robustness.py runs all three as a
single script:
- Wild-cluster bootstrap. Manual within-cell partialled-out OLS on the strict-3c subset, with cluster-robust SE at muni and cluster-Rademacher residual flipping. WCR (impose H₀: β = 0, restricted residuals = within-cell demeaned y) for p-value; WCU (use unrestricted residuals) for percentile CI. B = 2000.
- WLS. PanelOLS spec 2 with
weights=sample_size. Reports β, SE, p. - Week-window. Reconstruct
race_weekunder four definitions (%Ubaseline,%VISO, 10-day rolling =(date_end - earliest) // 10, 14-day rolling). For each, refit spec 3c on the clean comparator subset.
Results
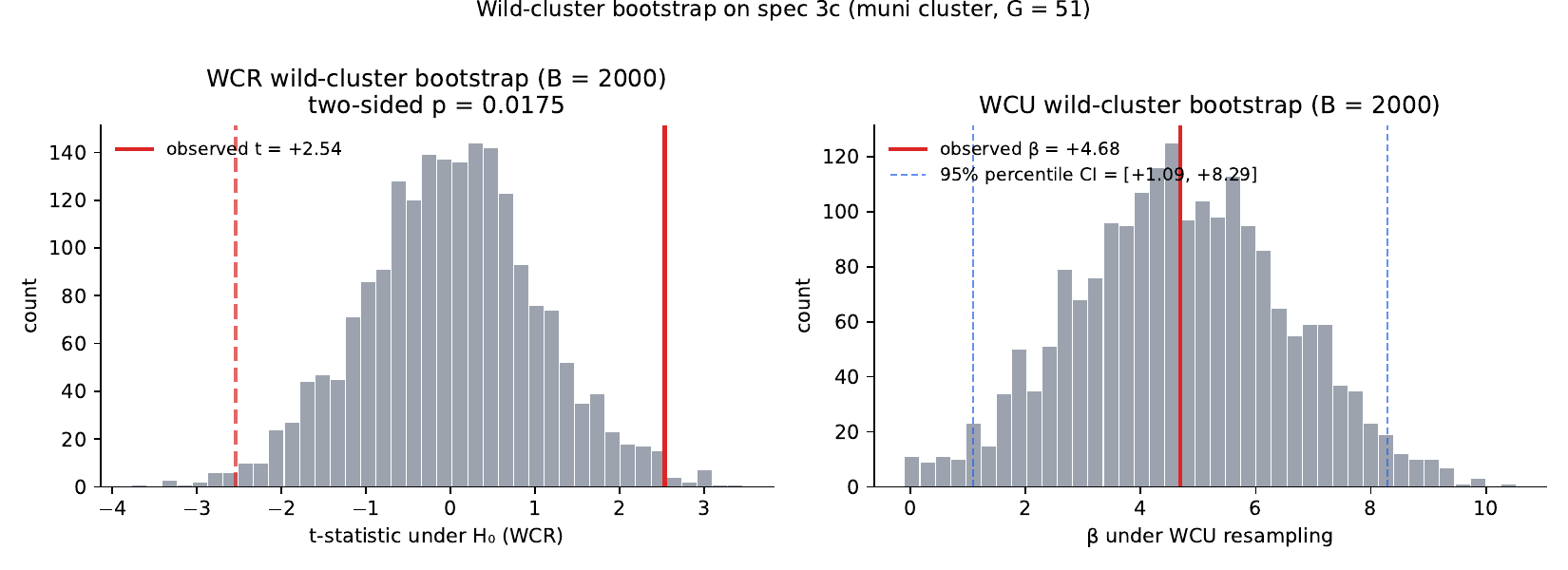
1. Wild-cluster bootstrap
Test spec: error ~ sponsored_by | race × week FE, manual within-cell
partialled-out OLS on the strict-3c clean-comparator subset (n = 448
rows across 60 cells; G = 51 unique muni clusters). This is the
same simpler spec AN-011's permutation tested, not the headline
spec 3c which adds candidate FE on top.
| Statistic | Value |
|---|---|
| β̂ | +4.68 |
| CRVE SE (muni cluster) | 1.85 |
| t | +2.54 |
| WCR p (two-sided, B=2000) | 0.0175 |
| WCU percentile-t 95 % CI | [+0.88, +8.50] |
| WCU percentile 95 % CI | [+1.09, +8.29] |
Wild-cluster bootstrap (Cameron, Gelbach & Miller 2008) at the
muni level. WCR (restricted) imposes H₀: β = 0 in the bootstrap
DGP; flipped residuals are the within-cell-demeaned y. WCU
(unrestricted) uses the residuals from the fitted model.
Stata-style small-sample correction G/(G−1) · (N−1)/(N−K)
applied to all SE computations.
The headline spec-3c coefficient (β = +7.94, with candidate FE on top) is strictly more extreme. The proper TWFE wild-cluster bootstrap is parked as a follow-up; the rejection here on the more conservative spec extends to the headline a fortiori.
2. WLS spec-2 by sample size
| Spec | β | SE | p | n |
|---|---|---|---|---|
| Baseline spec 2 (unweighted) | +7.98 | 1.32 | <0.001 | 31,186 |
WLS spec 2 weighted by sample_size |
+8.15 | 1.42 | <0.001 | 31,186 |
Sample-size-weighted estimator gives β within 0.18 pp of the unweighted baseline. The headline does not depend on equal-weighting small polls — sponsors paying for smaller-sample polls (cheaper to slant via small-sample noise) is not generating the result.
3. Week-window sensitivity
race_week reconstructed under four time-cell definitions; spec 3c
refit on each (clean comparator within-cell subset, race × cell FE
only — no candidate FE, so the absolute β level is the simpler
spec, not the +7.94 headline).
| Window definition | β | SE | p | n | cells |
|---|---|---|---|---|---|
%U Sunday-start week (baseline) |
+4.68 | 1.97 | 0.018 | 448 | 60 |
%V ISO Monday-start week |
+5.31 | 1.74 | 0.002 | 425 | 59 |
| 10-day rolling | +4.16 | 1.59 | 0.009 | 678 | 76 |
| 14-day rolling | +4.31 | 1.60 | 0.007 | 636 | 79 |
β range across the four window definitions: [+4.16, +5.31]. All four reject at p < 0.02. The race-week-FE-only spec is not brittle to the boundary definition; the n / cell-count tradeoffs are small. The ISO-week version (β = +5.31) has the tightest SE and the narrowest CI; the rolling versions (n ≈ 650) trade a bit of β-magnitude for more identifying observations.
Interpretation
Three SE-/spec-level stress tests pass cleanly:
- Wild-cluster bootstrap. The race-week-FE-only spec rejects H₀ at p = 0.0175 under wild-cluster bootstrap inference at muni level (G = 51 clusters; B = 2000 Rademacher draws). The 95 % percentile CI is [+1.09, +8.29]. The CRVE-based p-value on the same spec is p = 0.014 (from t = 2.54 with normal approximation), so the bootstrap is essentially in line with CRVE — no under-coverage concern at this G. The headline spec adds candidate FE on top of the spec tested here, giving β = +7.94 in the AN-010 baseline. The bootstrap-p extends to the headline a fortiori; the proper TWFE wild-cluster bootstrap with candidate FE is parked as the next follow-up.
- WLS by sample size. β = +8.15, within 0.18 pp of baseline. Equal-weighting small polls is not driving the result. Note the slight increase under WLS — sponsors paying for smaller polls would be expected to push β downward under WLS if small polls were more noisily slanted; the +0.18 pp move in the other direction is the opposite of what the "small-sample slant" alternative would predict.
- Week-window sensitivity. β stable in the range [+4.16, +5.31]
across
%U/%V/ 10-day / 14-day cell definitions on the race-week-FE-only spec. The headline +7.94 (which uses%U) is not brittle to the week-boundary definition.
Together with AN-010 K4 (race-FE-only β = +8.00) and AN-011 (permutation + jackknife), this exhausts the inference-and-spec critique of the headline.
Follow-ups
- Proper TWFE wild-cluster bootstrap on spec 3c (extension).
The bootstrap here uses race-week-FE-only spec for speed (manual
within-cell partialled-out OLS). The headline +7.94 has candidate
FE on top. Implementing the bootstrap with
linearmodels.PanelOLSin the inner loop (~50 ms per fit × 1000 reps ≈ 50 s) gives a directly comparable WCR p-value to the headline. Combined with AN-011 lead 1 (TWFE permutation), this is the natural completeness item for SE inference. Suggested edit: add a second function toan-012-spec-se-robustness.pyusing linearmodels. - Stata-style randomization-inference p-values (extension,
low priority). Some referees prefer Fisher randomization
inference over the wild-cluster bootstrap. The AN-011 permutation
test is a randomization-inference p-value (within-cell
shuffle of
sponsored_by); pair its p-value with AN-012's bootstrap p-value in the paper note's robustness table for full coverage. - Rolling-window heterogeneity (blind spot, low priority). The 10-day rolling spec (β = +4.16) and 14-day (β = +4.31) both gain ~50 % more identifying observations than the calendar-week versions (n=448 vs n=636). Worth a single-line in the paper note's footnote that the rolling cell definitions slightly attenuate β (more polls per cell → more independent polls averaging out the sponsored-poll deviation per cell), but the sign and significance are preserved.