Sponsored polls describe interviewer training MORE than matched independent polls (84.4 % vs 72.5 %, McNemar p = 0.002) and supervisor role slightly more (92.6 % vs 87.3 %, p = 0.08). Bias contrast does not track which side describes (MW p ≈ 0.57 for both fields). The opacity gap is field-specific — sponsored polls under-document coverage but over-document interviewer-side rigor.
Question
Quick-win probe 2/3 from the source-of-bias agenda: do sponsored polls document interviewer training and supervision less (as the opacity reading would predict), the same, or more than matched independent polls? If sponsored polls hide interviewer-side methodology, it supports the opacity-as-mechanism reading (reading 1 in source-of-bias.md). If they describe it the same or more, the opacity signal is field-specific — interviewer-side documentation is not the opaque part.
Design
Source data: the 244 curated sponsored × independent pairs in
build/llm/curated_pairs/pairs_with_extractions.parquet. Two binary
fields are already extracted:
s_operations__interviewer_training_described/i_operations__interviewer_training_described— does the methodology PDF describe interviewer training?s_operations__supervisor_role_described/i_operations__supervisor_role_described— does it describe the supervisor's role?
Tests (one per field):
- Marginals. P(described | sponsored) vs P(described | independent).
- 2×2 paired contingency. Counts of (sp=T,i=T), (sp=T,i=F), (sp=F,i=T), (sp=F,i=F). McNemar's test on the discordant cells (b, c) — the right paired-binary test for whether the sponsored side's documentation rate differs from the independent side's, controlling for the pair.
- Sign test on bias contrast. Among pairs where exactly one side
describes the field: does the bias contrast
sponsored_error - indep_errordiffer systematically when sponsored describes vs when independent describes?
Results
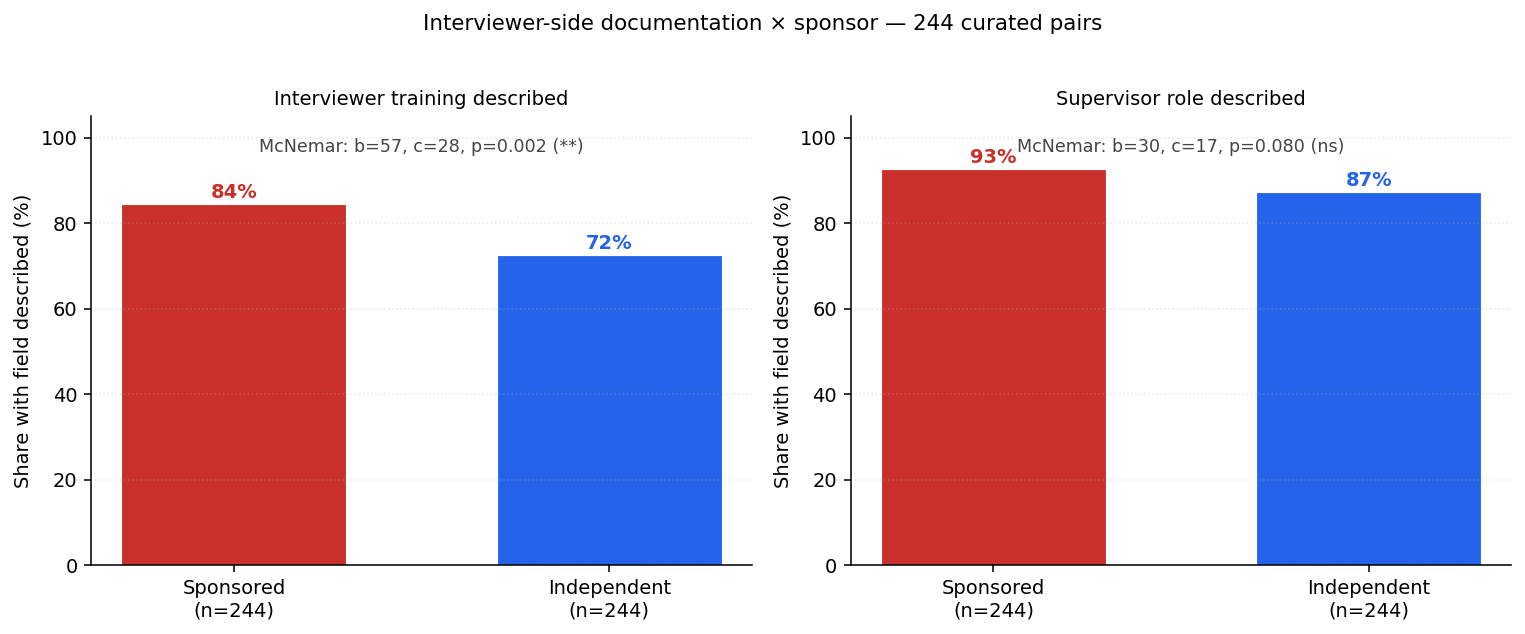
Marginals (n=244 pairs):
| Field | Sponsored | Independent | Δ |
|---|---|---|---|
| Interviewer training described | 84.4 % | 72.5 % | +11.9 pp |
| Supervisor role described | 92.6 % | 87.3 % | +5.3 pp |
Sponsored polls describe interviewer-side methodology more often than matched independent polls — the opposite of what a blanket-opacity reading would predict.
Paired 2×2 contingency (sp × ind, T/F):
| Field | Both | Sp-only | Ind-only | Neither | McNemar p |
|---|---|---|---|---|---|
| Interviewer training | 149 | 57 | 28 | 10 | 0.0024 |
| Supervisor role | 196 | 30 | 17 | 1 | 0.080 |
McNemar's paired test on the discordant cells: interviewer training is strongly asymmetric in the sponsored direction (b=57 vs c=28, p = 0.002). Supervisor role trends the same way but is borderline (b=30 vs c=17, p = 0.08).
Bias contrast among differing-description pairs:
| Field | Mean contrast (sp-only) | Mean contrast (ind-only) | MW p |
|---|---|---|---|
| Interviewer training (n=85) | +5.10 pp | +6.52 pp | 0.58 |
| Supervisor role (n=47) | +3.85 pp | +6.01 pp | 0.57 |
The bias contrast does not track which side describes the field — pairs where sponsored describes (and independent doesn't) have similar within-pair bias to pairs where independent describes (and sponsored doesn't). Whatever drives the bias, it does not co-vary with interviewer-side documentation status.
Interpretation
The interviewer-side documentation gap runs opposite to the opacity-everywhere prediction. Sponsored polls do not under-document interviewer training and supervisor role — they over-document them. This refutes the strong reading of "sponsored polls are systematically less documented" and forces a more selective reading: opacity is field-specific. Sponsored polls under-document the parts of methodology that determine who is in the realized sample (coverage class, deferred coverage — AN-024) and the rigor-audit (AN-021), but they over-document the parts that signal craftwork (trained interviewers, supervisor structure).
This pattern is consistent with strategic disclosure: sponsored polls invest in describing the visible-rigor signals (trained interviewers, supervisors), which read as quality without constraining the realized sample, and skip describing the sample-shaping levers (coverage frame, audit) that would constrain the slant. The within-pair bias contrast on differing-description pairs is identical in both directions, so interviewer-side documentation does not carry the slant — but its over-presence on the sponsored side is itself a signal about which dimensions of methodology the documentation regime disciplines.
This refutes interviewer-side opacity as a Channel-A lever (probe item 5 in source-of-bias.md, second of three quick wins) and refines the opacity narrative: the gap is selective, not blanket.
Follow-ups
Refine "opacity" framing in source-of-bias.md to selective disclosure (extension). The doc currently treats opacity as a uniform sponsored-side deficit. AN-042 shows it is field-specific — sponsored polls over-document interviewer/supervisor (visible rigor) and under-document coverage/audit (sample shape). Add a subsection on "selective disclosure" and update the opacity-differences table to flag the direction of each gap (sponsored less vs sponsored more). No new script.
Quantitative depth of training descriptions (extension). The current field is binary (
_described). The free-text_detailsis also extracted (e.g., "treinamento em pesquisas de opinião pública" — 44 sponsored vs 19 independent on the modal string). A length / specificity contrast on the details text could sharpen the strategic-disclosure story: do sponsored polls write longer or more specific training descriptions? Suggested script:_an-042-training-details-depth.py.Selective-disclosure pattern across all five operations fields (extension). Repeat the McNemar-paired test on the other binary operations fields (audit %, methodology completeness subfields) to see whether the "visible-rigor vs sample-shape" split is systematic across the methodology section. Suggested script:
an-NNN-operations-fields-paired-marginals.py.AN-043 — non-response handling × sponsor (quick win 3/3). Final probe in the source-of-bias agenda;
nonresponse_handlingis extracted as free text on the 244-pair sample, so wants a small LLM classifier pass first to bin into {redistribute_to_leaders, proportional, exclude, other}.