Pooled empirical DEFF* = 12.59 across 673 race × week × candidate cells with ≥3 independent polls (median cell DEFF* = 3.93, P75 = 9.59); realized cross-poll SD on a candidate's share is ≈ 5.0 pp, well above the binomial + DEFF≤3 model. Explains AN-109's miscalibration and qualifies AN-108's per-poll-loud reading: against the empirical cross-firm noise floor (not the binomial benchmark), a +7 pp single-poll shift is ≈ 0.8 SDs — within the noise floor. Aggregate regression β survives because N=568 averages the noise out. Informative about reputation / auditability comparators, not about channel decomposition.
Question
AN-109 surfaced that a binomial-SE-based blind audit on the within-candidate × race × week comparator has a 30–60 % false- positive rate on independent polls across DEFF ∈ {1, 1.5, 2, 2.5, 3}, against a nominal 5 %. That means realized cross-poll variance in race × week × candidate cells substantially exceeds binomial + DEFF≤3. To know whether (a) the true sampling DEFF is meaningfully higher than the 1.5–2.5 rule of thumb or (b) the excess variance comes from non-sampling sources (week-window drift, firm/mode differences), we need to estimate it directly from the data.
The empirical DEFF here is defined as $DEFF^* = \widehat{\mathrm{Var}}(\text{poll_percent}) / \overline{\mathrm{Var}_{\text{binom}}}$ within race × week × candidate cells with ≥3 independent polls. It absorbs everything — real design effect, within-week share drift, firm and methodology heterogeneity, nonresponse-handling differences. It is an upper bound on the pure sampling DEFF and a lower bound on the residual variance an outside auditor faces. The headline number directly calibrates the SE inflation an AN-109 v2 would need to apply for a calibrated blind audit.
Design
Sample: build/assemble/cand_poll.parquet, restricted to
matched_share == 1.0, finite poll_percent, sample_size > 0,
and poll_is_independent == 1. Group by (politico_id, race_week)
with race_week = muni_id + "_" + field_period_week. Keep cells
with K_c ≥ 3 distinct polls.
Per cell c (K_c polls of candidate i in race × week w):
- $\widehat{\mathrm{Var}}c = \mathrm{Var}{ddof=1}(\text{poll_percent}1, \ldots, \text{poll_percent}{K_c})$ in pp².
- $\overline{\mathrm{Var}{\text{binom},c}} = \frac{1}{K_c}\sum{k=1}^{K_c} 100^2 \cdot p_k(1-p_k)/n_k$ in pp².
- $DEFF_c^* = \widehat{\mathrm{Var}}c / \overline{\mathrm{Var}{\text{binom},c}}$.
Pooled estimator (regulator-relevant):
$$ \widehat{DEFF}^* = \frac{\sum_c (K_c - 1), \widehat{\mathrm{Var}}c}{\sum_c (K_c - 1)} \Bigg/ \frac{\sum_c (K_c - 1), \overline{\mathrm{Var}{\text{binom},c}}}{\sum_c (K_c - 1)} $$
(Weighted by within-cell degrees of freedom; both numerator and denominator on the same weights.)
Reports.
- Distribution of cell-level $DEFF_c^*$: median, P25, P75, P90, mean (unweighted across cells and weighted by $K_c$).
- Pooled $\widehat{DEFF}^*$.
- Sensitivity splits:
n_candidates_in_race∈ {2, 3, 4, ≥5} — does competitiveness drive the excess?- sample-size tertile (low / mid / high) — does the ratio shrink where n is larger?
- field_period_week half (pre- vs post-median week) — temporal pattern?
Caveat. $DEFF^$ here is *everything not binomial. It cannot be decomposed into sampling DEFF vs week-drift vs firm-heterogeneity without a firm × day decomposition.
Results
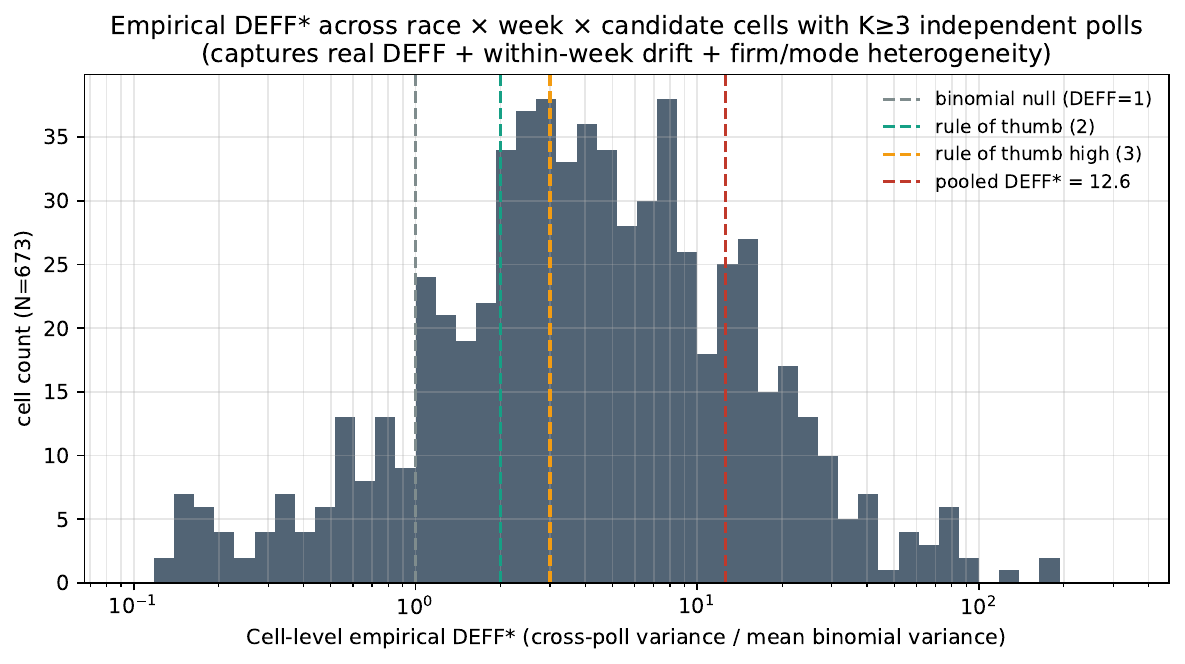
Sample. 2,475 independent polls across 673 (politico_id × race_week) cells with K ≥ 3 polls per cell (median K=3, 1,802 cell- within degrees of freedom). 672 cells return a finite DEFF*.
Headline (overall):
| statistic | value |
|---|---|
| pooled $\widehat{DEFF}^*$ | 12.59 |
| pooled observed variance (pp²) | 24.64 |
| pooled binomial variance (pp²) | 1.96 |
| median cell-level DEFF* | 3.93 |
| P25 — P75 cell DEFF* | 1.81 — 9.59 |
| P90 cell DEFF* | 19.51 |
| mean cell DEFF* (unweighted) | 16.21 |
| mean cell DEFF* (poll-weighted) | 15.05 |
| frac cells with DEFF* < 1 | 14.0 % |
| frac cells with DEFF* < 2 | 28.0 % |
| frac cells with DEFF* < 3 | 41.8 % |
| frac cells with DEFF* < 5 | 57.1 % |
Realized cross-poll SD on a candidate's share = √24.64 ≈ 5.0 pp under the pooled estimator — well above what a binomial + DEFF≤3 model would predict (≈ 2.0–2.4 pp on a typical median-n poll).
Sensitivity splits (pooled DEFF* per scope):
| split | n_cells | median cell DEFF* | pooled DEFF* |
|---|---|---|---|
| overall | 673 | 3.93 | 12.59 |
| n_candidates = 2 | 10 | 7.64 | 9.86 |
| n_candidates = 3 | 54 | 6.76 | 17.18 |
| n_candidates = 4 | 73 | 4.54 | 8.47 |
| n_candidates ≥ 5 | 530 | 3.69 | 12.44 |
| sample size — low (<700) | 216 | 4.36 | 12.32 |
| sample size — mid (700–1000) | 219 | 3.80 | 16.43 |
| sample size — high (≥1000) | 238 | 4.32 | 8.29 |
| week half — early (<W38) | 194 | 3.51 | 23.30 |
| week half — late (≥W38) | 479 | 4.25 | 10.11 |
Every slice exceeds the 1.5–3 rule of thumb. Lowest-DEFF slice is high-n (8.29). Highest-DEFF slice is early weeks (23.30) — real share movement is largest early in the cycle, before candidates crystallize.
Interpretation
The empirical cross-poll noise floor is much wider than a binomial + rule-of-thumb DEFF model predicts. Pooled DEFF* ≈ 12.6 means the realized SE on a candidate's share at a single poll is about √12.6 ≈ 3.55× the binomial SE — under the empirical noise floor, a typical median-n sponsored poll has effective SE ≈ 8.84 pp on the candidate's share, not 2.49 pp.
Three consequences.
1. Explains AN-109's miscalibration. AN-109 reported false- positive rates of 30–60 % on independent protocols under binomial
- DEFF ≤ 3. A calibrated AN-109 v2 with the empirical DEFF* would inflate SE by √12.6 and produce nominal FP. The +13 to +19 pp excess detection rate on sponsored polls in AN-109 should largely collapse under empirical-DEFF calibration — most of those flagged sponsored polls would no longer fail the test. The remaining excess (if any) is the truly extreme tail.
2. Walks back AN-108's "per-poll loud" reading. AN-108 concluded the +7 pp shift is z ≈ 2.8 on the median sponsored poll against binomial SE — read as "the sponsor's pollster knows the bias is loud." Under the empirical noise floor, z = 7 / 8.84 ≈ 0.79. The per-poll-loud claim against an idealized binomial benchmark holds; against the realized cross-firm distribution it does not. A sponsor's pollster comparing their +7 pp shift to the universe of published polls of the same candidate sees a realization well within the typical 5 pp cross-firm SD — plausibly deniable as one realization from a noisy universe. AN-108's claim needs the comparator stated explicitly to remain honest.
3. The aggregate regression β survives precisely because N averages the noise out. β = +7 pp with cluster-SE at muni_id across n=568 sponsored cand-poll rows is detectable at the aggregate level even when each individual poll is buried in cross-firm noise. This is what a wide noise floor + a real mean-shift looks like: invisible per-poll, visible at scale.
The DEFF* decomposition is unidentified here. Pooled DEFF* = 12.59 absorbs (a) the true sampling DEFF (multi-stage cluster + quota, plausibly 1.5–3); (b) real share drift inside the 7-day race × week window; (c) firm-level methodology heterogeneity (mode, weighting, name rotation); (d) firm-level systematic bias — AN-016 documented per-firm β heterogeneity, so independent firms themselves carry persistent direction-bias. Distinguishing (a) from (b)+(c)+(d) requires firm × day-level structure not in this cut. The 12.59 is therefore an upper bound on pure DEFF and the right number for an outside auditor's "realized noise floor" question.
Implication for the AN-108 reading. AN-108's "per-poll loud" claim is comparator-dependent. It holds against an unbiased benchmark (binomial SE around the true share). It does not hold against the empirical cross-firm noise floor that the sponsor's pollster actually observes when checking against other published polls. A sponsor's pollster comparing their +7 pp shift to the realized universe of published comparators sees ≈ 0.8 SDs — within the cross-firm distribution. The asymmetry matters for the reputation / auditability reading (AN-108 is loud only if the observer has access to an unbiased benchmark) but is silent on whether the bias is generated via lawful design tilt or fabrication.
Follow-ups
AN-108 comparator-explicit qualifier (writing): AN-108's interpretation needs a paragraph making the comparator explicit (binomial / unbiased benchmark vs empirical cross-firm noise floor). Done within this /next iteration as step 5 propagation.
**AN-109 v2 with empirical DEFF*** (extension): re-run AN-109 with SE inflated by √12.59 (or by the empirical DEFF* of the matching split, e.g. early vs late weeks). Expectation: FP rate on independent protocols collapses toward nominal 5 %; sponsored detection rate also drops; the excess-detection gap shrinks but may persist if the bias is concentrated in the extreme tail of poll-percent. Suggested file:
an-NNN-an109-empirical-deff.py.DEFF* decomposition (blind spot / extension): separate the pooled 12.59 into (a) pure sampling DEFF, (b) within-week real share drift, (c) firm-mode-methodology heterogeneity, (d) firm- level systematic bias variance. Approach: cells with multiple polls of the same firm (same firm, same race × week) isolate sampling DEFF; cells with polls separated by 1 vs 7 days isolate drift; cross-firm same-day isolates methodology + firm bias. Likely requires day-level or firm × day-level data not all present in cand_poll. Suggested file:
an-NNN-deff-decomposition.py.Why is the early-week DEFF* 2.3× the late-week DEFF*? (puzzle): early weeks have DEFF* = 23.3 vs 10.1 in late weeks. Real share drift is the natural read (candidates not yet locked in), but could also be firm-mix changing (early entrants are a selected set). Cross-check with AN-073 firm × week distribution and with
days_to_electionpolynomial absorption. Suggested file:an-NNN-deff-by-week-decomposition.py.Regression robustness — does β=+7pp survive under empirical- DEFF-inflated clustered SE? (extension / robustness): the AN-001 / AN-002 cluster-SE at muni_id already absorbs some of the cross-poll dispersion. Re-do the headline regression with
wild_bootstrapor block-bootstrap at race × week, which should produce SEs reflecting the empirical noise floor. Expected: β stays at +7 pp; SE inflates; t-stat shrinks but remains significant. If t drops below 2, the aggregate result needs revision too. Suggested file:an-NNN-headline-robustness-empirical-noise.py.