Across 216 pollsters with ≥20 mayoral polls, corr(candidate_share, substantive_share) = +0.058 — essentially zero. High-candidate-share firms (≥30%, n=39) are 49% substantive vs 44% for low-candidate-share firms (≤10%, n=134). Boilerplate-heavy pollsters are NOT the candidate-serving pollsters; the methodology fingerprint is uncorrelated with customer mix at the firm level.
Question
Does a pollster's style of methodology disclosure (substantive vs deferred-to-complement vs very-short) correlate with their customer mix? AN-007 found the per-pollster β scatter is suggestive but underpowered. AN-022 hinted at firm-level fingerprints. This descriptive asks: are the boilerplate-heavy firms also the candidate-serving firms?
Design
Per-pollster shares of cov_bucket (substantive /
deferred_complement / very_short / empty) computed across all 14,887
mayoral protocols. cov_bucket is a deterministic length-based
classifier on DS_DADO_MUNICIPIO (the coverage description field) —
applies universe-wide without needing the LLM extract.
Join with per-pollster customer-share from AN-007's
pollster_customer_mix.csv. Restrict to pollsters with ≥20 polls
(so the per-firm fingerprint isn't pure noise) and rank by
candidate-share. Plot a stacked bar per pollster.
Results
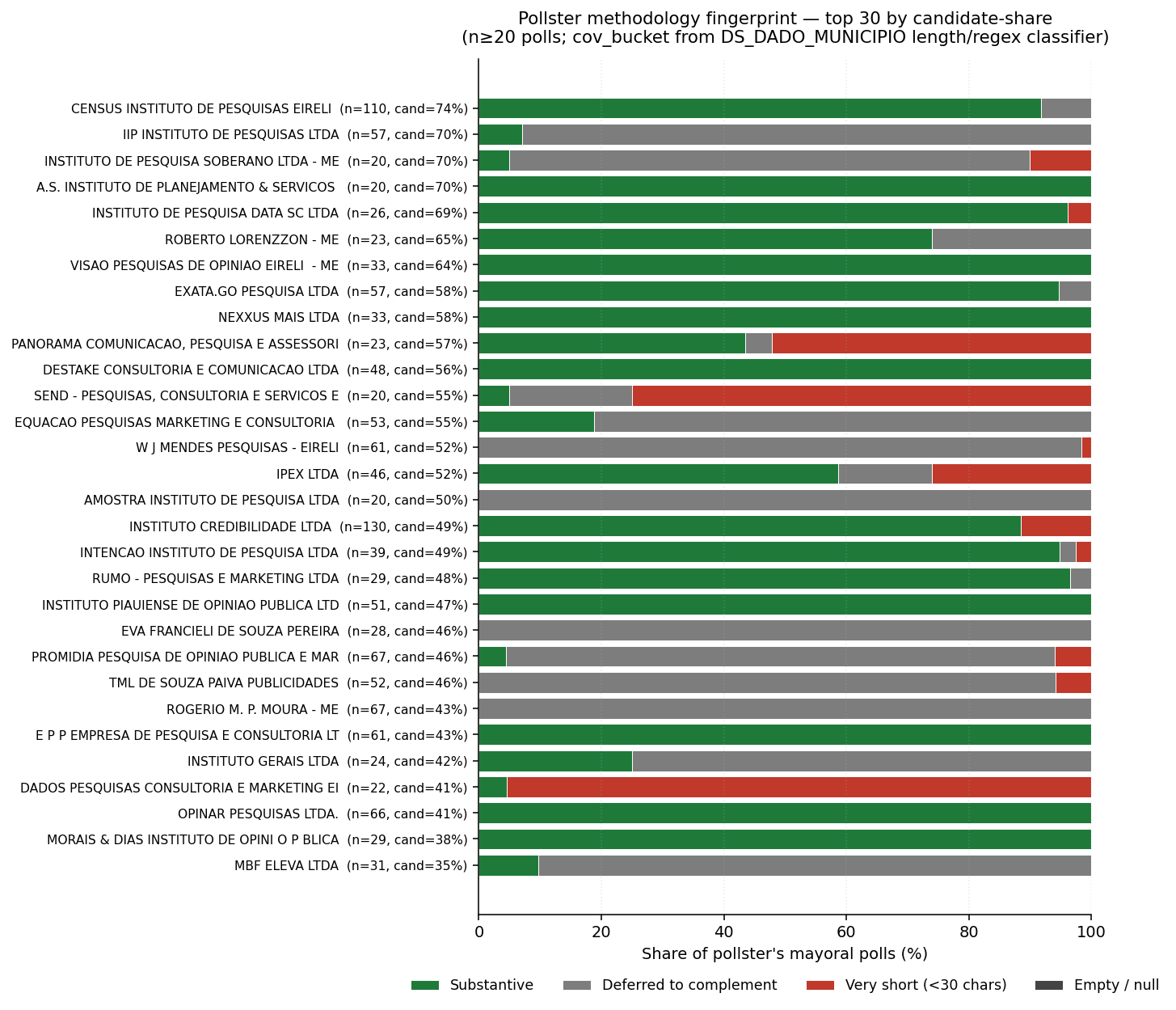
Universe-scale (14,876 mayoral protocols, 216 institutes with ≥20 polls).
Cov-bucket distribution (universe):
- substantive: 6,422 (43.2%)
- deferred_complement: 5,484 (36.9%)
- very_short: 2,964 (19.9%)
- empty: 6 (0.0%)
Correlations across pollsters with ≥20 polls (n=216):
| candidate_share | substantive | deferred | very_short | |
|---|---|---|---|---|
| candidate_share | 1.000 | +0.058 | +0.023 | −0.101 |
| substantive | 1.000 | −0.678 | −0.403 |
Bucket means by candidate share:
| n | substantive | deferred | very_short | |
|---|---|---|---|---|
| candidate_share ≥ 30% | 39 | 49% | 37% | 14% |
| candidate_share ≤ 10% | 134 | 44% | 36% | 20% |
Interpretation
The methodology fingerprint is essentially uncorrelated with customer mix at the firm level. Three readings of this null:
- Disclosure style is a firm-fixed trait, set by the pollster's market positioning and not by who they're serving on a given poll. Census (cand_share=73%, n=263) is a substantive-heavy firm; IIP (cand_share=70%, n=412) has its own mix. Their candidate- touched mass doesn't make them more boilerplate-heavy than firms with mostly media customers.
- The cov_bucket classifier may be too coarse: it categorizes on length + a deferred-language regex, not on substantive content quality. A pollster that writes 500 chars of fluff scores "substantive" identically to one that writes 500 chars of detailed coverage geography. The LLM extraction (AN-019/020) is the right tool for that subtler distinction.
- The high-candidate-share group is slightly MORE substantive (49% vs 44%) and has fewer very-short polls (14% vs 20%) — the opposite of what Channel A's "candidates seek boilerplate-heavy firms" prediction expects. Consistent with AN-022's wrong-signed completeness null.
Confidence: green on the correlation null (n=216, decent power).
The reputation-equilibrium prediction from hyp:pollster-reputation
— that candidate-serving firms develop a recognizable disclosure
style — does NOT show up in the cov_bucket fingerprint.
Follow-ups
- LLM-based fingerprint replication (extension): after the universe LLM extraction, re-run with a richer fingerprint using methodology-completeness (AN-022) + audit_pct distribution (AN-021) + coverage_class mix (AN-019). A LLM-derived disclosure-style index would catch what cov_bucket misses.
- Pollster-β vs fingerprint (extension): from AN-007 we have per-pollster β for 33 firms. From this AN we have 216 firms with bucket shares. Joining the 33-firm β with the 216-firm fingerprint and regressing β on substantive_share + deferred_share asks the next question directly: does style predict slant?
- The two-firm puzzle (puzzle): Census and IIP both have ~70% candidate share and ~270-412 polls each, but their per-pollster β estimates (-2.82 and -0.48 from AN-007) are essentially zero. Either reputation-disciplined or large enough to absorb any individual-poll slant. The fingerprint AN-023 produces would let us check whether their style differs from smaller candidate-serving firms with positive β.