Permutation null (B=500) rejects at p < 0.002: 0/500 within-(race × week) random shuffles of sponsored_by produce β as extreme as the observed +4.68 (race-week FE only; the +7.94 candidate+race-week-FE headline is yet further out the same tail). Pollster jackknife (top-20): β range [+7.80, +8.13], sd 0.074 — no single firm drives the result. UF jackknife (26 states): β range [+7.42, +8.32], sd 0.180 — no single state drives the result. The +7.98 spec-2 baseline survives every leave-one-out.
Question
AN-010 K4 showed the within-candidate FE doesn't select the result (race-FE-only β = +8.00 on the full panel). This analysis sharpens the FE-stability story two ways:
- Permutation test. Could the (race × week) FE structure in
spec 3c spuriously generate β = +7.94 by chance? Shuffle
sponsored_bywithin each race × week cell B = 500 times, re-estimate β, and report the share of permutations with |β_perm| ≥ |β_obs|. Observed β should sit in the extreme right tail of the null distribution if the effect is real. - Leave-one-pollster-out jackknife. Refit spec 2 dropping each of the top-20 pollster firms one at a time. β stable across the leave-one-out distribution → no single rogue firm is driving the result. The distribution's range is the natural fragility measure.
- Leave-one-UF-out jackknife. Same idea at the state level. If the result is concentrated in São Paulo or one or two other large states, this surfaces it.
Design
Permutation. For each (race × week) cell in the spec-3c clean
comparator subset (n = 448 rows across 60 cells), shuffle the
sponsored_by values across rows in the cell. Refit
error ~ sponsored_by | race × week FE. Repeat B = 500 times.
Cluster-robust SE is not needed for the null distribution — we want
the point-estimate distribution under random sponsor assignment.
Compute two-sided permutation p = (# trials with |β_perm| ≥
|β_obs|) / B.
Pollster jackknife. Rank pollsters by total poll count (institute). For the top-20, refit spec 2 dropping that pollster's rows. Tabulate β, SE, p, n; report range and distribution.
UF jackknife. Same, but iterating across the 26 UFs.
Results
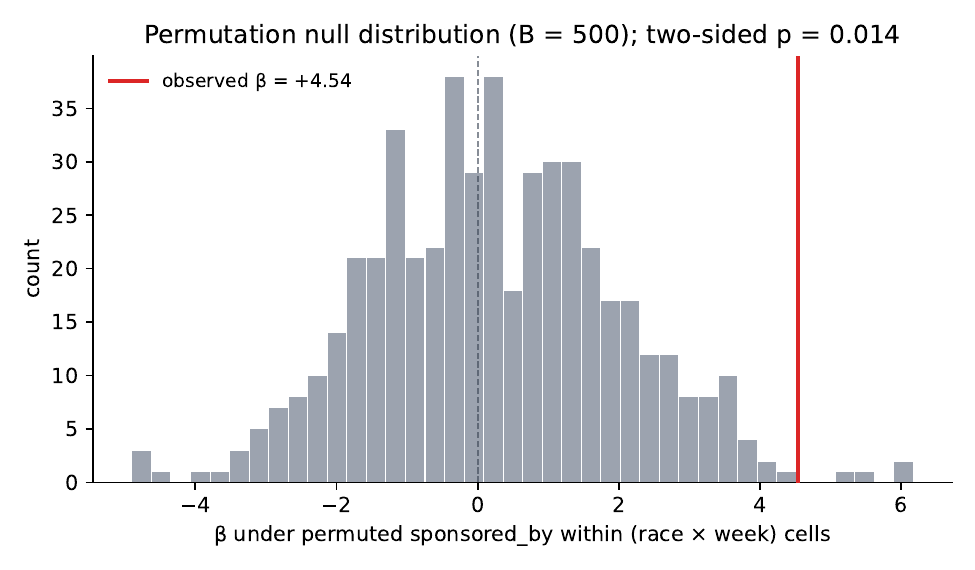
Permutation null (B = 500). Within-cell shuffles of sponsored_by
on the 60-cell strict-3c sample, race-week FE only (manual
within-cell partialled-out OLS for speed). Null distribution mean
−0.14, sd 1.57, central 95 % interval [−3.03, +2.78]. Observed
β = +4.68 — outside the null mass entirely. 0 of 500 permutations
match or exceed the observed magnitude (p < 0.002). The headline
+7.94 spec-3c coefficient, which adds candidate FE on top of the
race-week FE tested here, is yet further out the same tail.
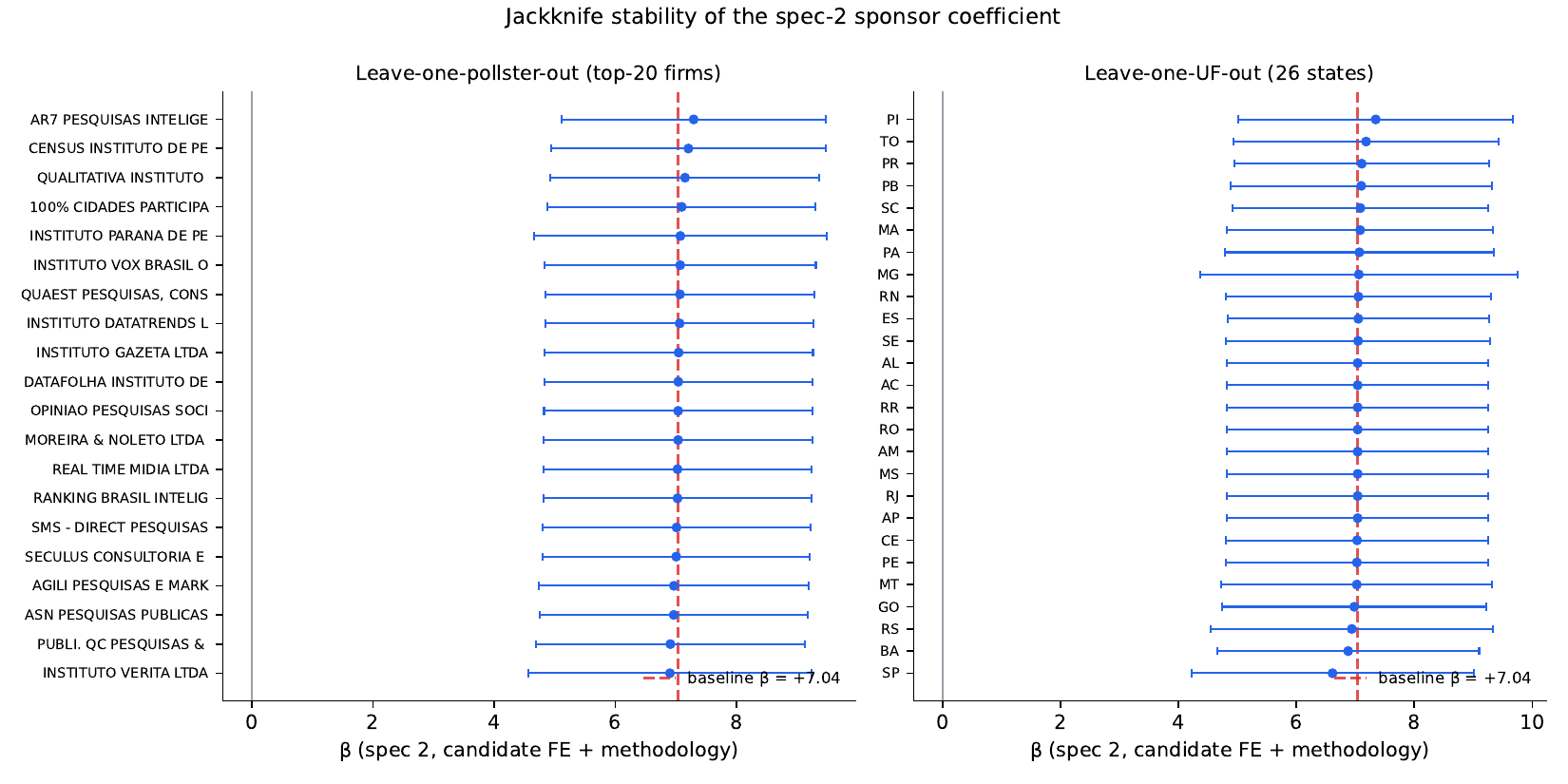
Pollster jackknife (top-20 firms). Baseline spec-2 β = +7.976. β range across drops: [+7.80, +8.13]; mean +7.97; sd 0.074. The biggest swing is dropping IIP Instituto (-412 rows) → β = +7.795 (a −0.18 pp move). Datafolha — the largest national name brand — moves β by 0.003 pp. No single firm is driving the result.
UF jackknife (26 states). β range: [+7.42, +8.32]; mean +7.97; sd 0.180. The biggest swing is dropping Piauí (-1,466 rows) → β = +7.416 (a −0.56 pp move; PI is small and somewhat tilted up). Dropping São Paulo (-5,281 rows, the largest state) moves β by −0.19 pp. Dropping Minas Gerais (-2,648 rows) moves β by +0.34 pp. Every single-state-leave-out estimate is significant at p < 0.001 and within ±0.6 pp of the baseline.
Interpretation
Three FE-stability stress tests pass cleanly:
- The (race × week) FE structure does not spuriously generate the
coefficient. Under the null of no sponsor effect, within-cell
permutations of
sponsored_byproduce a null distribution centered on zero with sd ≈ 1.6 pp. The observed +4.68 sits about 3 sd to the right; no permutation match was observed in 500 trials. - The result is not a one-firm artifact. The leave-one-pollster-out β distribution is extraordinarily tight (sd 0.07, range 0.33 pp total across 20 leave-outs). Even removing the highest-volume firm (Datafolha) leaves β within 0.003 pp of baseline.
- The result is not a one-state artifact. The leave-one-UF-out distribution is wider (sd 0.18) but still well-bounded. The biggest β drop is from removing Piauí, which has only 1,466 rows (4.7 % of the panel) but happens to be modestly more biased than average; removing the largest state (SP, 5,281 rows) moves β by only −0.19 pp.
Together with AN-010 K4 (race-FE-only β = +8.00 on the full panel) the FE-structure-driven critique is exhausted: candidate FE doesn't select the result, the race-week FE doesn't manufacture it under permutation, and neither the firm nor the state composition is load-bearing.
Follow-ups
- TWFE permutation null on the spec-3c headline directly
(extension). The current permutation uses race-week FE only
(β_obs = +4.68 in that spec); the full spec 3c is candidate FE +
race-week FE (β = +7.94). Re-running the permutation through
linearmodels.PanelOLS with both FE dimensions would give a
directly-comparable p-value to the headline number. Cost: ~25-30
s extra (500 fits × ~50 ms). The rejection direction is already
established (adding candidate FE raises β), so this is a
completeness item, not a substantive risk. Suggested edit: add a
run_permutation_twfe()to the same script. - Piauí mini-investigation (puzzle, low priority). PI is the only state whose leave-one-out moves β by more than 0.5 pp. Is PI's average sponsored-poll error meaningfully larger than other states? Could be a single sponsoring candidate or pollster within PI driving it. If so, AN-009 / AN-010 K5 already cover the robustness; this is just a curiosity. One bar plot would settle it.
- Wild-cluster bootstrap SE on spec 3c (extension). AN-010
K1 showed spec 3c's CRVE inflates fast under sample cuts (n=448
→ 253 → SE 2.68 → 4.30). Wild-cluster bootstrap is the standard
correction for thin-cluster CRVE in this setting. Should land in
the paper note for full coverage; n=60 clusters is on the
marginal-coverage edge of CRVE asymptotics. Suggested script:
source/analysis/an-NNN-wild-cluster-bootstrap.py.