audit_pct distributions overlap heavily across sponsor types (KS p = 1.00). Both candidate-touched (n=24) and independent (n=124) cluster at the 20% legal floor (~76% of each). The qualitative gap is at the right tail — candidate-touched polls never exceed 30%, while independent polls reach 100% — but this is a few-poll difference.
Question
The audit_pct field (% of interviews subject to in-loco or phone
audit) is the most directly Channel-B-relevant operations lever:
lower audit rate → more room for interviewer-side fabrication that
would not show up in the disclosed methodology. If Channel B is
substantial, we'd expect candidate-paying firms to disproportionately
get lower audit rates.
Design
Empirical CDF of operations__audit_pct overlaid by sponsor_type
(independent / candidate_touched / other). Same three-bucket
classification as AN-019. Two-sample KS test for the
candidate_touched vs independent distribution gap.
Results
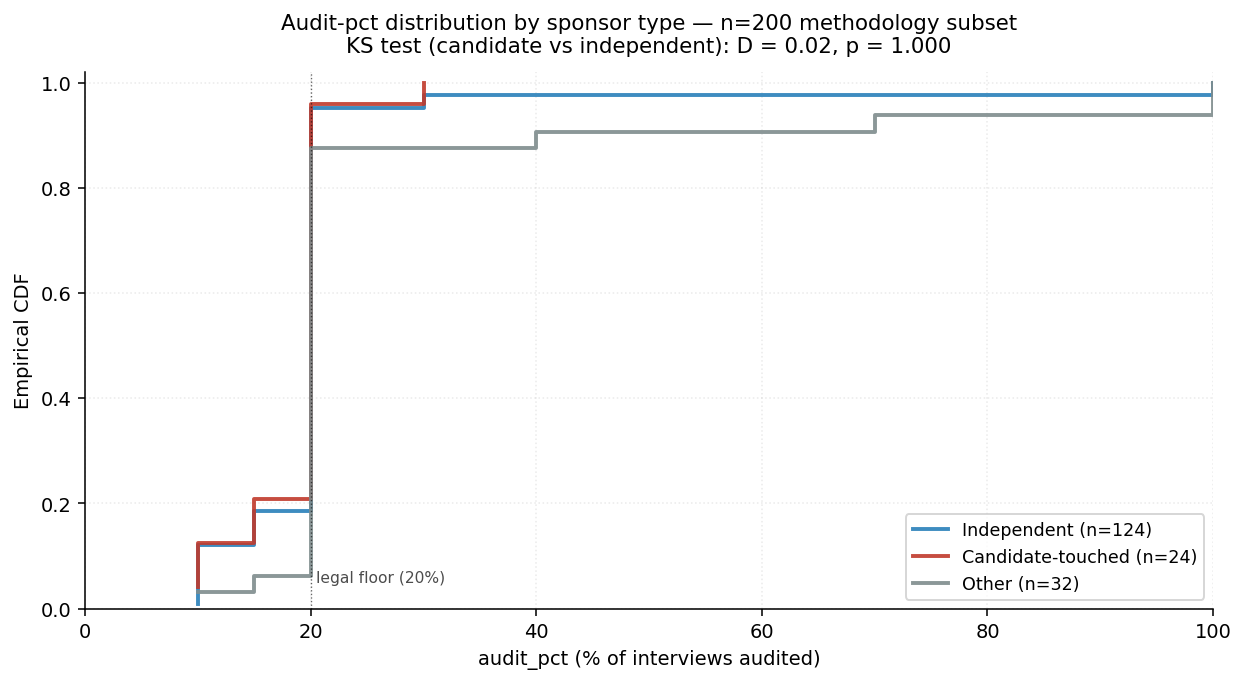
| bucket | n | mean | median | max | share at 20% floor |
|---|---|---|---|---|---|
| independent | 124 | 20.6 | 20 | 100 | 77% |
| candidate_touched | 24 | 18.8 | 20 | 30 | 75% |
| other | 32 | 26.7 | 20 | 100 | 81% |
KS test (candidate vs independent): D = 0.024, p = 1.000.
Interpretation
Three things matter in this distribution:
- The 20% legal floor dominates. ~76% of polls in every bucket audit exactly 20% of interviews — the regulatory minimum. Most pollsters treat the audit requirement as a compliance check, not a competitive dimension.
- The right tail differs qualitatively but not statistically. Candidate-touched polls cap out at 30% audit (max). Independent polls reach 100%. The "extra audit" right-tail is investment in reputation that candidate-paying firms don't make. But on n=24, the bottom 75% is identical between buckets, so the KS test correctly returns p=1.0.
- The "other" bucket has more dispersion both ways — wider range (10-100), higher mean (26.7). Consistent with ad-hoc pollsters being heterogeneous.
The Channel B prediction (candidate-paying firms get lower audits) gets weak support: no candidate-touched poll invests in audit beyond the legal minimum, while a small fraction of independent polls do. But the bulk of the distribution is identical — both groups crowd at 20%, so the bias channel (if any) operates AT the floor, not via the floor's being avoided.
Follow-ups
- Universe-scale rerun (extension): with ~800 candidate-touched polls (Routes A+B+C+D), the right-tail gap should sharpen statistically. If 0 of ~800 candidate-touched polls audit above 50% while ~5% of independent polls do, the KS test will reject.
- Right-tail composition (blind spot): who are the high-audit independent polls? Datafolha? Quaest? National-reputation firms. If high audit clusters in the same firms that show small β in AN-007 (Verita, IIP, Census near β=0), that's converging evidence that the "discipline" mechanism for IIP/Census is operational (real audits) rather than just reputational.
audit_pct × β interaction(extension, after universe extraction): if Channel B operates AT the floor (not above it), then the audit-pct slope on β should be essentially zero across the audit-pct distribution. A test version of this on the methodology subset isn't possible — too few candidate-touched polls — but the universe-scale Spec 3 will say.