Money does NOT drive the rank gradient in self-sponsoring. The AN-027 two-mechanism interpretation of safe-race rank-1 over-commissioning as 'resourcing without strategic need' is REFUTED on the literal money-control test. Baseline rank-2 vs rank-1 gap is −3.6 pp tight / −3.6 pp mid / −6.8 pp wide; under log(revenue) control it moves to −3.6 / −3.6 / −6.6 — essentially unchanged across all margin tertiles. log(revenue) main effect is +0.23 pp per log-unit (p=0.16 pooled); rank × log(revenue) interactions are all <0.012 pp / log-unit and insignificant (p>0.17). The cross-margin pattern (rank-1 dominance largest in safe races) is robust to money control. Substantive read: the safe-race rank-1 over-commissioning is real but is NOT explained by campaign-finance revenue. Alternative resourcing channels (campaign sophistication, party support, fixed-cost crossing of the polling-affordability threshold) remain candidates; pure-money resourcing as a stand-alone mechanism is not supported.
Question
AN-027 / AN-028 proposed a two-mechanism story for the AN-026 selection finding: in TIGHT races runners-up over-commission for coordination-demand reasons; in WIDE races leaders over-commission because they have resources to spend on non-strategic uses (donor signaling, GOTV planning). AN-029 tests the resourcing leg directly: does adding campaign-finance revenue as a control attenuate the safe-race rank-1 dominance while preserving the tight-race rank patterns?
Results
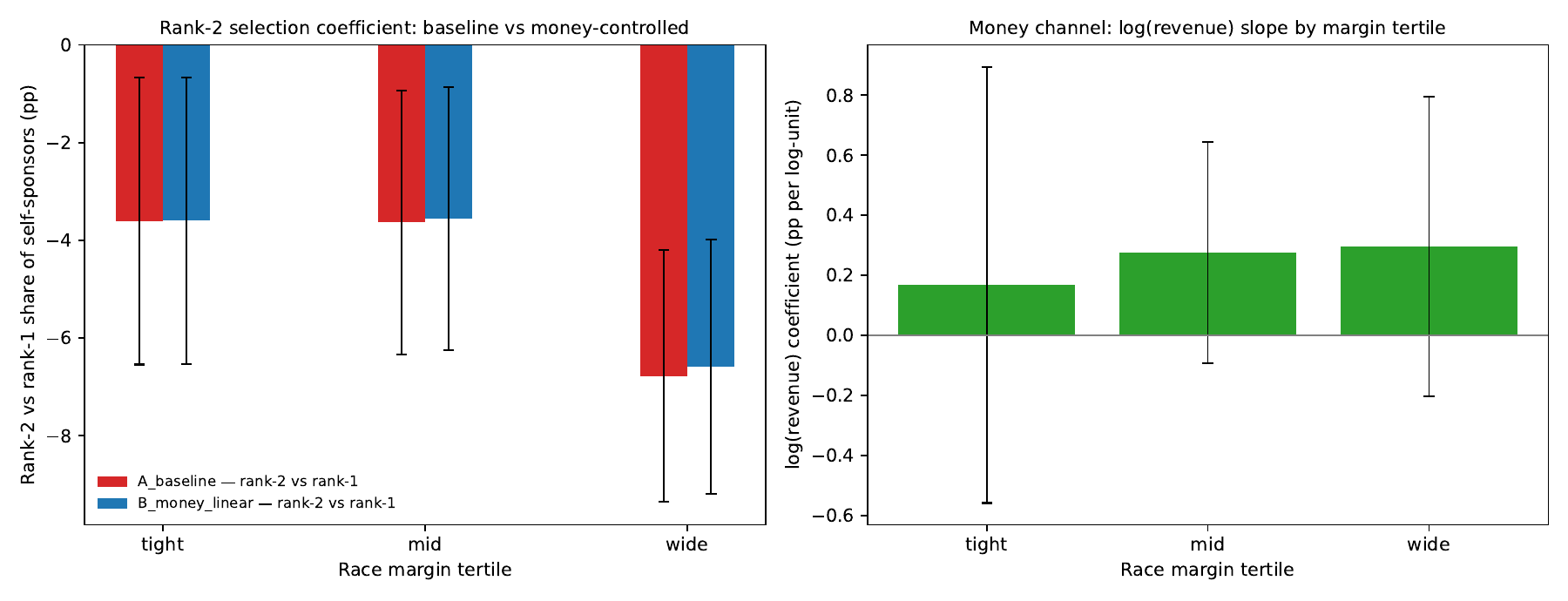
Rank coefficients (vs rank-1 reference) — Spec A baseline vs Spec B with log(revenue)
| Stratum | Term | A baseline (pp) | B + log(revenue) (pp) | Δ |
|---|---|---|---|---|
| All margins | rank-2 | −4.76*** | −4.69*** | +0.07 |
| rank-3 | −6.91*** | −6.57*** | +0.34 | |
| rank-4 | −8.76*** | −8.21*** | +0.55 | |
| rank-5+ | −10.60*** | −9.78*** | +0.82 | |
| log(revenue) | — | +0.23 (p=0.16) | — | |
| Tight margin | rank-2 | −3.61** | −3.60** | +0.01 |
| rank-3 | −6.44*** | −6.24** | +0.20 | |
| rank-4 | −10.36*** | −10.04*** | +0.32 | |
| rank-5+ | −14.27*** | −13.78*** | +0.49 | |
| log(revenue) | — | +0.17 (p=0.65) | — | |
| Mid margin | rank-2 | −3.63** | −3.56** | +0.07 |
| rank-3 | −6.68*** | −6.27*** | +0.41 | |
| rank-4 | −7.52*** | −6.79*** | +0.73 | |
| rank-5+ | −8.62*** | −7.55*** | +1.07 | |
| log(revenue) | — | +0.28 (p=0.14) | — | |
| Wide margin | rank-2 | −6.78*** | −6.59*** | +0.19 |
| rank-3 | −7.57*** | −7.02*** | +0.55 | |
| rank-4 | −7.91*** | −7.07*** | +0.84 | |
| rank-5+ | −6.66*** | −5.33** | +1.33 | |
| log(revenue) | — | +0.30 (p=0.25) | — |
Race FE (muni) absorbed in all specs. n_cohort = 8,225, n_self = 428.
Spec C — rank × log(revenue) interactions
All four interaction coefficients are small (≤+0.012 pp / log-unit) and all insignificant (p ∈ [0.17, 0.99]). Money does not operate differentially across ranks. The rank-1 main effect of log(revenue) in spec C is −0.003 pp / log-unit (p = 0.76), so there's no evidence that rank-1 candidates' self-sponsoring is more responsive to money than other ranks'.
Interpretation
Money is not the resourcing channel. The rank gradient is essentially unchanged after adding log(revenue) as a control — across all margin tertiles, after race FE, and whether money is modeled as a linear control or interacted with rank. The log(revenue) coefficient itself is positive but small (+0.2 to +0.3 pp per log-unit) and statistically insignificant except as a weak overall signal.
Cross-margin pattern survives. The safe-race rank-1 dominance (rank-2 vs rank-1 gap = −6.8 pp wide vs −3.6 pp tight) is real, robust, and not attenuated by money. The tight-vs-wide difference in rank gradient is therefore not the "money channel" but something else.
The AN-027 / AN-028 interpretation (safe-race leaders commission for resourcing reasons) is REFUTED on its literal money-revenue form. The AN-027 finding (rank-2 over-commissioning in tight races under rank-at-commission framing) is a separate test that this iteration didn't address — it uses final_rank, not rank-at-commission, per the user-specified scope.
What could drive safe-race rank-1 dominance if not money? Plausible alternatives the AN-029 design doesn't separate:
- Campaign sophistication — well-organized campaigns commission polls regardless of marginal need; well-organized campaigns also tend to win safe races. Revenue is a noisy proxy for sophistication.
- Polling fixed cost — a real poll costs ~R$50k–200k, which is a fixed cost. Above some threshold of revenue, more money doesn't buy more polls. The continuous log(revenue) control mis-specifies this; a threshold indicator might bind differently.
- Party institutional inertia — established parties have in-house pollsters and standard practices that commission polls on behalf of their candidates, independent of the candidate's own revenue.
- Selection on candidate quality — competent candidates win AND commission polls; rank-1 over-commissioning is then a quality confound, not a strategic-incentive one.
The companion paper should pick one or two of these to operationalize rather than letting "resourcing" stand as an ungrounded label.
Caveats:
- Revenue is
valor_receita_totalsummed across all receita_2024 line items per candidate, including in-kind, party transfers, etc. Some of these are mechanically tied to party support rather than candidate-side fundraising capacity. - The LPM specification absorbs muni effects but doesn't account for selection into running for prefeito; the self-sponsoring rate conditional on running is the outcome.
- Final-rank coding (per user spec) — the AN-027 rank-at-commission framing would give a different baseline pattern. A clean money-control test on the AN-027 rank-at-commission cohort is the natural follow-up.
Follow-ups
Rank-at-commission + money control (extension, highest paper value): re-run AN-029 using rank-at-commission (from AN-028's date_start anchor) instead of final_rank. The tight-race rank-2 over-commissioning that AN-027 documented under rank-at-commission should survive money control if the coordination story holds — but AN-029 hasn't tested this directly yet.
Threshold-based money control (extension): replace log(revenue) with an indicator for "revenue above the cost of one polling contract" (~R$50k or ~R$100k). If polls have fixed costs, the relevant question is whether the candidate crossed the threshold, not the marginal log-revenue slope.
Campaign sophistication proxies (blind spot): try alternative resourcing measures — number of paid staff, advertising spend, in-kind contributions — and see if any attenuates the rank gradient where log(revenue) doesn't.
Decisions.md candidate (framing update): AN-029 is a null on the resourcing interpretation. If this finding becomes load-bearing for the companion paper's section on selection mechanisms, the "two-mechanism" framing from AN-027/028 needs revision and should be flagged as a decisions.md entry: drop "resourcing" as a stand-alone mechanism; report safe-race rank-1 over-commissioning as an unexplained selection fact that future work needs to mechanize.