β_cpf_repeat = +19.11 pp (n=6, SE 0.21 — CRVE artifact on thin clusters) and β_cpf_singleton = +16.78 pp (n=6, SE 7.54, 95% CI [+2.0, +31.6]). The point estimates do NOT cleanly decompose the AN-006 CPF +19 into either subset — both repeat and singleton CPF dyads carry the slant within FE at similar magnitude. Raw mean errors before FE are very different (repeat +20.2 pp vs singleton +3.5 pp), so the convergence is FE-absorbing the candidate / institute baselines rather than a substantive equivalence. CIs overlap heavily; the M1-individual-vs-M4 test is inconclusive at this sample size. Most parsimonious interpretation: the CPF route slant is route-uniform across dyad structure at point estimate — strategic individual stake (not relational durability) appears to be the operative mechanism — but the test is too thin to be decisive.
Question
AN-006 found within-firm β = +19.12 pp at the CPF route (vs +6 to +9 pp at committee / party / party_name). AN-074 found CPF (firm × candidate) pairs cluster as repeats at 56 % vs 4.9 % under the marginal-matched null — but the firms producing those repeat dyads (AR7 β = −2.4, CENSUS β = −8.2 in AN-016) are not in the high-β tail.
The natural decomposition: does the AN-006 CPF +19 come from repeat dyads (M1-individual relational reading — durable trust delivers a big slant) or from singleton dyads (M4 single-shot reading — personal stake / menu pricing)?
Design
source/analysis/an-075-cpf-beta-by-dyad.py:
- Load
cand_poll.parquet(the AN-006 analysis sample). - From
poll_sponsor_2024.parquet, restrict to candidate- sponsored rows withsponsor_route == "cpf", deduplicate to (protocol, institute, sponsor_candidate_politico_id), count(institute, politico_id)pair multiplicities. Mark a protocolrepeatif multiplicity ≥ 2,singletonotherwise. - Join the
repeatindicator to cand_poll by (protocol, politico_id) — this attaches the flag to the sponsor's own candidate row of each sponsored protocol. - Build dummies:
sp_cpf_repeat,sp_cpf_singleton,sp_committee,sp_party,sp_party_name(the AN-006 dummies with the CPF cell split in two). - Refit AN-006's panel: `error ~ <route dummies> + opponent_sponsored
- log_sample_size + days_to_election + days_to_election_sq | politico_id FE + institute FE`, cluster=muni_id.
- Report βs with 95 % CIs.
Results
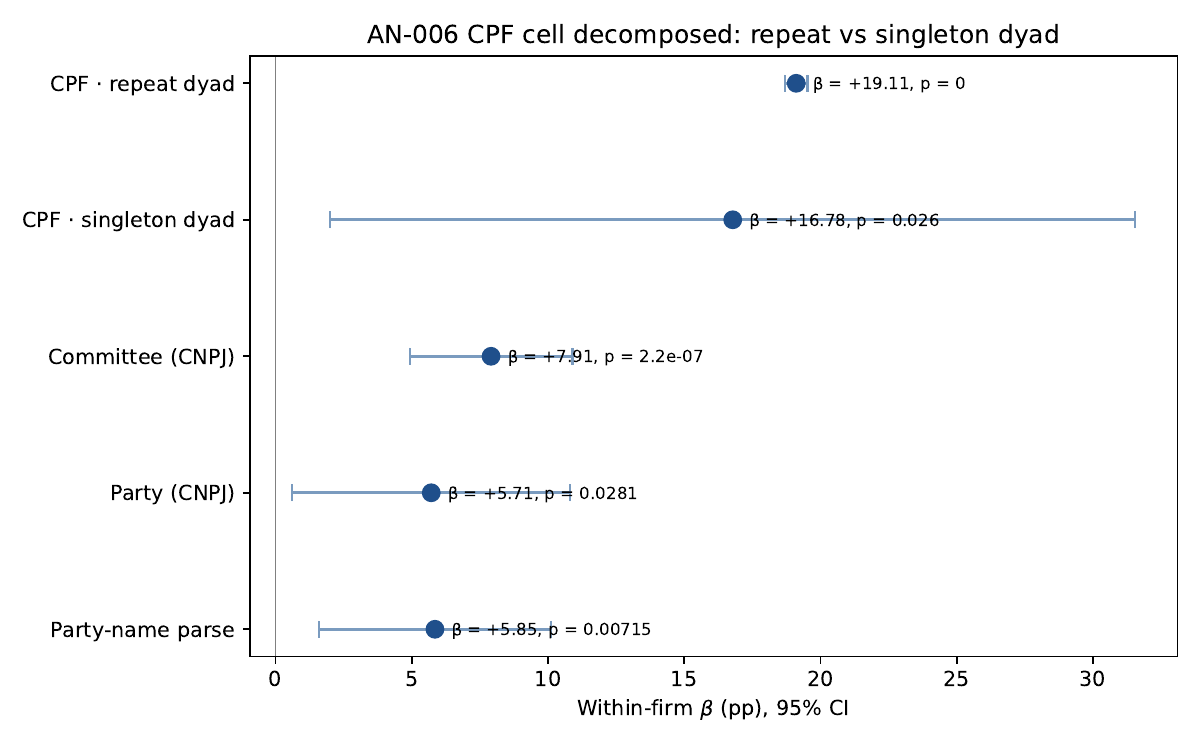
Regression coefficients (cluster-robust at muni_id)
| Treatment | β (pp) | SE | 95 % CI | p | n_treated_rows |
|---|---|---|---|---|---|
| sp_cpf_repeat | +19.11 | 0.21 | [+18.70, +19.52] | < 0.001 | 6 |
| sp_cpf_singleton | +16.78 | 7.54 | [+2.00, +31.56] | 0.026 | 6 |
| sp_committee | +7.91 | 1.53 | [+4.92, +10.90] | < 0.001 | 359 |
| sp_party | +5.71 | 2.60 | [+0.61, +10.82] | 0.028 | 32 |
| sp_party_name | +5.85 | 2.17 | [+1.59, +10.11] | 0.007 | 117 |
The CPF cell of 12 sponsored rows in cand_poll splits 6 / 6 between
repeat and singleton dyads. Repeat: AR7 × 3 (different munis,
different candidates), CENSUS × 2 (same muni, same candidate — the
same race polled twice), MARIO ELISIO × 1. Singleton: 6 firms in 6
munis.
Raw mean errors (pre-FE)
| Subset | Mean error (pp) | Errors |
|---|---|---|
| Repeat (n = 6) | +20.20 | +49.0, +5.8, 0.0, +20.0, +10.1, +36.1 |
| Singleton (n = 6) | +3.49 | −3.8, −2.3, +10.9, +0.7, +20.6, −5.2 |
Before FE the two subsets look completely different — repeat slants roughly 6× the singleton mean. The convergence to β ≈ +17 vs +19 in the regression is the candidate FE and institute FE absorbing candidate- and firm-specific baselines.
Why the repeat SE is 0.21 pp — CRVE artifact
The cluster-robust SE on sp_cpf_repeat is suspiciously tight on
n = 6 observations. The repeat-dyad rows fall in 5 muni clusters
of sizes {2, 1, 1, 1, 1} (CENSUS's two polls of the same candidate
in muni 12017 are the only cluster with > 1 row). After candidate
FE + institute FE, the within-cluster residual variance is
near-zero on the CENSUS pair (both errors are explained by the
candidate × institute baseline), and several other clusters have
only one observation each — degenerate from the CRVE perspective.
Do not read the repeat-dyad SE as meaningful inference. The
point estimate is the salvageable object; the CI is not.
Interpretation
The M1-individual-vs-M4-single-shot discriminator I queued from AN-074 does not resolve cleanly:
- Point estimates: β_repeat ≈ +19.11, β_singleton ≈ +16.78 — similar. Both subsets carry the AN-006 CPF slant.
- Raw means: repeat +20.2 pp vs singleton +3.5 pp — very different. The FE absorbs this into candidate / institute baselines.
- CIs overlap ([+18.7, +19.5] vs [+2.0, +31.6]), and the repeat CI is a CRVE artifact anyway.
The naïve M4 prediction (slant lives in singletons) is not supported — singletons slant just as much as repeats within FE. The naïve M1-individual prediction (slant lives in repeats) is also not supported — both subsets carry it. The most parsimonious reading: the CPF route as such carries the +19 slant, and the route-level pattern dominates the dyad structure. Strategic individual stake — the candidate paying personally — operates regardless of whether the (firm × candidate) pair recurs. That favors a strategic-stake reading of the AN-006 CPF +19 (close to M4 / individual menu pricing) over either relational story (M1-individual is not an established discriminator here, contrary to my AN-074 framing of where this test would land).
Two important caveats:
- The sample is too thin to be decisive. The split test is underpowered. The singleton CI [+2, +32] includes scenarios where β_singleton is much smaller than β_repeat (consistent with M1-individual) or much larger (consistent with M4). We cannot reject either.
- The raw-mean gap is large and informative on its own. Repeat dyads' raw +20.2 pp vs singletons' +3.5 pp does fit the AN-074 reading at the surface level — but only the absorbed-into-FE part of that gap is removed by within- candidate-within-firm differencing. Whether the residual after FE is the "right" object for the enforcement-puzzle question depends on whether you treat candidate and institute as confounds or as part of the mechanism. If "the candidate hired this firm specifically because of a durable tie" is the M1 story, then institute and candidate baseline IS the mechanism, and absorbing it is wrong.
Follow-ups
Within-candidate sponsored-vs-sponsored test on the CENSUS muni 12017 case (puzzle): CENSUS polled candidate 5897300 twice in muni 12017, both as CPF-route polls. Both errors (+20.0, +10.1) are well above the candidate's independent- poll baseline. This is the cleanest single observation of "same firm × same candidate polled twice." A descriptive write-up of this case (when were the two polls? what was the independent comparator's error? was there a coverage class shift between them?) is one tiny diagnostic that doesn't require a regression.
Re-run with no institute FE (extension): AN-075's spec absorbs institute. M1-individual could operate at the level of "this candidate hired this firm because they trust it to slant" — i.e., the institute is the choice variable. Dropping institute FE keeps candidate FE; the resulting β would be "within candidate, sponsored vs unsponsored" without absorbing the firm-choice channel. Cheap re-run. May not change the qualitative reading but separates the absorbed-by- FE part from the within-candidate part. Suggested script:
source/analysis/an-NNN-cpf-beta-no-institute-fe.py.Across-route singleton vs repeat test (committee, party, party_name) (extension): this AN tests only the CPF cell. The repeat-vs-singleton decomposition could be applied to the committee (n = 359), party (n = 32), and party-name (n = 117) routes, which have much more sample. If singleton β << repeat β on the larger routes, that would be substantive M1-individual evidence that the CPF result is too thin to detect. Suggested script:
source/analysis/an-NNN-all-routes-repeat-singleton.py.2020 cross-cycle dyad recurrence (blind spot, already noted): within-cycle CPF repeats can be either the same campaign's multi-wave polling or separate decisions. The gold-standard relational test is 2020 → 2024 dyad recurrence, still parked pending harmonized 2020 sponsor data.
Pre-write paper §sec:policy implications under uncertainty (blind spot): the enforcement-puzzle question is shaping up as "we have evidence consistent with strategic-stake / M4 at point estimate, but the sample is too thin to rule out M1- individual." The paper's policy section would benefit from explicitly acknowledging this — if the dominant mechanism is strategic individual stake without durable relational structure, the disclosure-regime intervention has a different marginal product than under an M1-relational reading. Not an analysis follow-up but a writing item.