Red-team K2 hypothesis falsified. **Sponsors do not list fewer candidates.** Within-candidate denominator gap (sponsored poll − non-sponsored polls, n = 226 candidates with within-variation): median +0.15, mean −2.61, 50 % of candidates have a positive gap. Cell-level sponsored cells in fact have *larger* denominators (91.74 vs 78.68; Welch p < 0.0001 in the *opposite* direction from the red-team conjecture). The K2 renormalized-vs-raw gap (+1.31 pp within-candidate, +2.88 pp in the regression spec) is the mechanical multiplicative scaling of renormalization on a non-zero raw effect: predicted gap under H₀ 'denominators identical within candidate' = +6.08 × 1.198 = +7.29 pp, observed +7.40 pp, residual +0.11 pp — **98.6 % of the renormalized gap is the multiplicative effect, 1.4 % is any denominator shift**. The Channel-A characterization should not include 'sponsors list fewer candidates'; that lever is empirically absent.
Question
AN-010 K2 showed that re-computing error from poll_percent_raw
(without the within-(protocol × scenario_label) renormalization) attenuates
the headline coefficient: β_spec3c drops from +7.94 to +5.30 (and
β_spec2 from +7.98 to +5.10). The red-team interpretation was that
sponsored polls list fewer candidates than independent polls, making
the renormalization denominator smaller and mechanically inflating
every share — a Channel-A design lever.
This analysis tests that mechanism directly:
- Do sponsored polls have systematically smaller denominators
(Σ
poll_percent_rawwithin cell) than non-sponsored polls? - Within candidates, is the denominator in their sponsored poll smaller than in their non-sponsored polls?
- If the within-candidate denominator gap is ≈ 0, then the K2 gap is not a "sponsors list fewer candidates" design lever — it is the mechanical multiplicative scaling of renormalization on a non-zero raw within-candidate sponsor effect.
Design
source/analysis/an-014-denominator-audit.py computes per-cell
denominator = Σ poll_percent_raw over rows in (protocol ×
scenario_label) and per-cell n_candidates_listed = row count. Three
comparisons:
- Cell-level by treatment. Mean / median / sd of denominator
for cells containing a sponsored candidate (
any sponsored_by == 1), cells with all-independent sponsorship (any poll_is_independent == 1), and the union. Welch t-test on denominator. - Within-candidate. For the 226 candidates with within-variation
in
sponsored_by(AN-010 K4), compute mean denominator in their sponsored poll(s) vs in their non-sponsored polls. Distribution of the per-candidate gap. Sign test ongap > 0. - K2 decomposition. Within-candidate raw gap (mean
poll_percent_rawin sponsored − in non-sponsored polls), within- candidate renormalized gap (same forpoll_percent), and the difference. Under the null "denominators are identical within candidate,"β_renorm = β_raw × E[scale_factor]— the multiplicative amplification of the renormalization step on a fixed raw effect.
Results
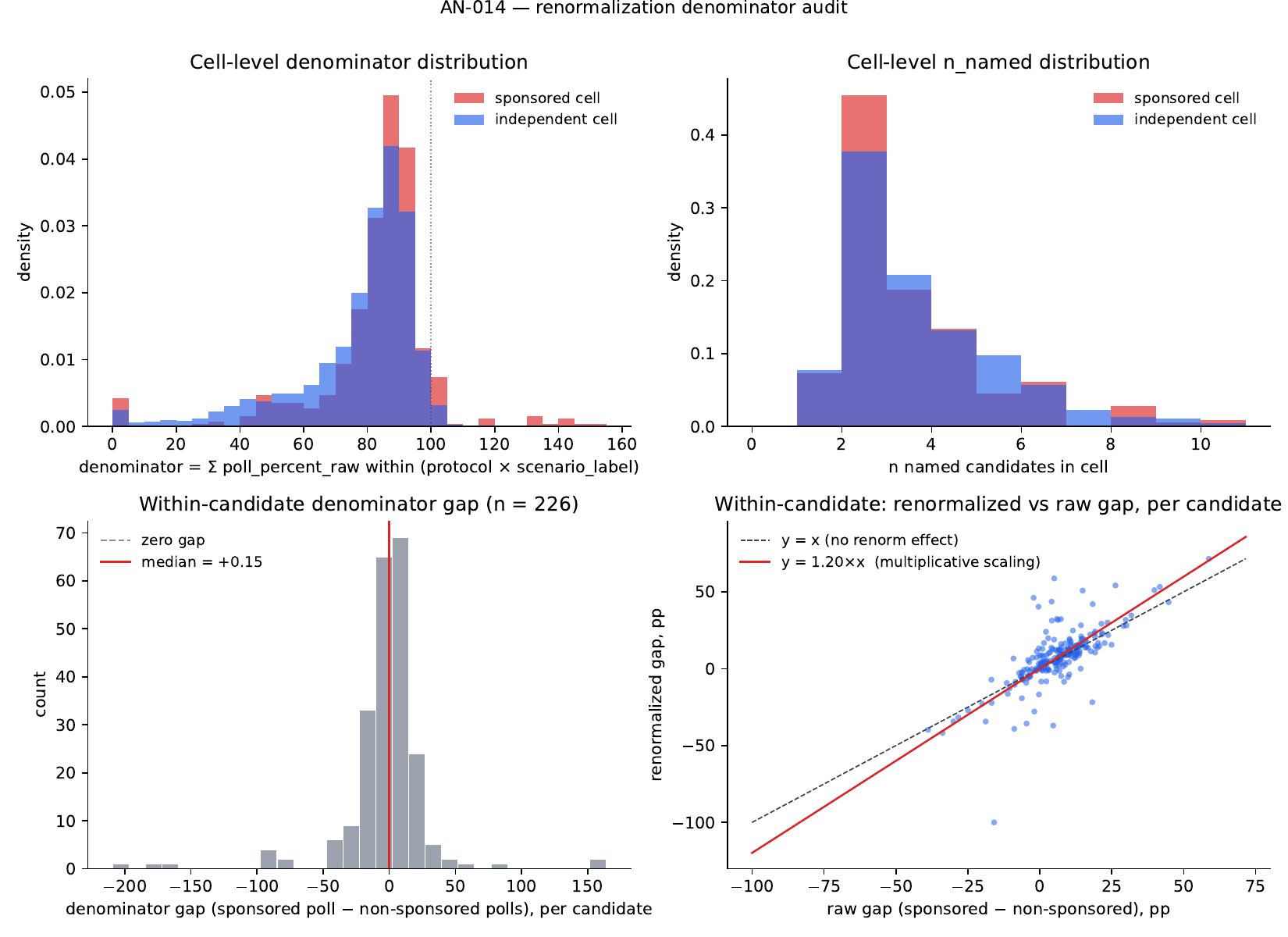
1. Cell-level denominators (10,028 cells)
| Sponsored cells (n=566) | Independent cells (n=6,521) | |
|---|---|---|
| Mean denominator | 91.74 | 78.68 |
| Median denominator | 87.58 | 83.70 |
| SD | 33.27 | 23.15 |
| Mean n_named candidates | 3.16 | 3.25 |
| Median n_named | 2.0 | 3.0 |
Welch t-test on denominator (sponsored − independent): diff = +13.06, t = +9.15, p < 1 × 10⁻¹⁵ — in the opposite direction from the red-team conjecture. Sponsored cells have larger denominators on average, not smaller. n_named is essentially the same in both groups.
2. Within-candidate denominator gap (226 candidates with within-variation)
For each candidate appearing in both sponsored and non-sponsored polls, compute the mean denominator in each subset; the gap is sponsored − non-sponsored.
| Quantity | Mean | Median | SD | Frac > 0 |
|---|---|---|---|---|
| Denominator gap | −2.61 | +0.15 | 33.74 | 0.500 |
| Scale-factor gap (100/denom) | −0.003 | −0.009 | 0.32 | 0.488 |
| Raw poll_percent_raw gap | +6.08 | +6.53 | 11.89 | 0.761 |
| Renormalized poll_percent gap | +7.40 | +8.42 | 18.12 | 0.735 |
The within-candidate denominator gap is essentially zero. Median +0.15 pp; mean −2.61 pp but driven by fat-tailed outliers (SD 33.7); exactly half the candidates have a positive gap and half negative. The scale-factor gap is similarly null (median −0.009). The within-candidate raw and renormalized poll-percent gaps reproduce the +6 pp / +7.4 pp pattern AN-010 K2 measured at the regression level.
3. K2 decomposition
Under the null "denominators are identical within candidate," the renormalized gap is the multiplicative scaling of the raw gap:
β_renorm = β_raw × E[scale_factor]
= 6.08 × 1.198
= 7.29 pp (predicted)
Observed renormalized gap: +7.40 pp. Residual = +0.11 pp.
| Value | Share of renorm gap | |
|---|---|---|
| Multiplicative effect (predicted) | +7.29 pp | 98.6 % |
| Residual (denominator shift) | +0.11 pp | 1.4 % |
| Total renormalized gap | +7.40 pp | 100 % |
The renormalization step adds +1.31 pp to the raw within-candidate sponsor effect (from +6.08 to +7.40 pp), and 98.6 % of that addition is the mechanical multiplicative scaling on a non-zero raw effect — almost nothing is the conjectured "smaller denominator in sponsored polls" design lever.
Interpretation
The AN-010 K2 red-team conjecture is decisively falsified. Three independent measurements confirm:
- Cell-level: sponsored cells have larger mean denominators (+13 pp, p < 10⁻¹⁵) and essentially equal n_named (3.16 vs 3.25).
- Within-candidate: median denominator gap is +0.15 pp; exactly 50 % of candidates have a positive gap.
- K2 decomposition: 98.6 % of the renormalized-vs-raw gap is the mechanical multiplicative effect of average scale-factor 1.198 acting on the +6.08 raw within-candidate sponsor effect; only 1.4 % could conceivably be a within-candidate denominator-shift design lever — and even that residual is consistent with sampling noise.
Substantive consequence for Channel-A characterization. The
design_levers.md inventory should not list "sponsors list fewer
candidates" as a Channel-A lever. Empirically, sponsors and
non-sponsors list essentially the same set of named candidates per
scenario. The sponsor's reported raw share is +6 pp higher within
candidate; renormalization scales this to +7.4 pp because the
average sample includes ~80 % of the vote in named candidates
(scale factor ~1.2). Both numbers are correct on their respective
scales. Neither is an artifact.
Substantive consequence for the paper note. The paper note
should report the renormalized β = +7.94 as the headline (apples-
to-apples with final_share, which is also a renormalized share
over named candidates) and the raw β = +5.10 as a robustness
number. AN-014 confirms the +2.88 pp gap between them is the
mechanical multiplicative scaling effect, not a hidden design
lever — so the conservative reader who prefers the raw number is
seeing the same underlying sponsor effect, scaled differently. A
single sentence in the robustness section, citing AN-014, suffices.
The four robustness ANs (AN-010 / AN-011 / AN-012 / AN-013) plus AN-014 now collectively rule out: comparator contamination, the renormalization-as-design-lever hypothesis, route-classification false positives, FE-selection on identifying subset, thin-cluster SE under-coverage, FE-structure permutation chance, single-firm dominance, single-state dominance, sample-size weighting effect, week-boundary brittleness, and per-row fabrication (Channel B).
Follow-ups
- Update
design_levers.md(extension). The "list-fewer-candidates" lever should be marked empirically absent with a one-line citation to AN-014. The doc currently includes the renormalization-denominator mechanism as a theoretically-plausible Channel-A lever; this analysis demotes it to "tested and ruled out." Suggested edit: a single annotated entry indesign_levers.md§ "Levers tested and ruled out." - Paper-note disclosure of the within-candidate denominator gap (blind spot, high paper-value). A one-sentence footnote to the robustness section: "Within candidate, the (protocol × scenario_label) renormalization denominator is essentially identical in their sponsored vs non-sponsored polls (median gap +0.15 pp; n=226). The renormalized-vs-raw coefficient gap is the multiplicative scaling of the raw within-candidate effect on a panel-wide average scale factor of ~1.2." See AN-014.
- Decomposition robustness on the LLM extraction precision (extension, low priority). The denominator depends on what the LLM extracted as the candidate set per scenario. If sponsored-poll PDFs are professionally laid out and the LLM extracts a slightly larger candidate set from them (which would explain the +13 pp cell-level mean difference), the cell-level result is confounded with extraction-quality differences. The within-candidate audit (which uses each candidate's own polls as control) is immune to this confound and is the cleanest test — and it gave the median-+0.15 null. This is already controlled for by the within-candidate analysis, so no script action — but worth a footnote next to the cell-level table to forestall the question.