id: an-013
hypothesis: headline-sponsor-bias
headline: "Crude per-candidate post-fielding tampering ruled out by within-sponsored-poll digit forensics; broader fabrication channels NOT ruled out. Round-number frequency indistinguishable between sponsor's own candidate (18.2 % integers) and other candidates in the same sponsored poll (17.7 %; A vs B z=+0.26, p=0.79). Mult-of-5 indistinguishable (4.1 % vs 3.7 %; z=+0.45, p=0.66). Tenths-digit distribution for values ≥ 5 has the same shape across A and B (digit-0 share 20.4 % vs 20.3 %). Group A's Benford first-digit shift toward 4–5–6 vs B's 1–2–3 reflects sponsors polling viable candidates (30–60 % range), not numerical manipulation: Group B inside the same sponsored polls follows Benford normally. Blind spots of this test: sophisticated manipulation that preserves digit distributions, proportional within-poll rescaling, and any pre-publication data work (quota reweighting, dropping strata, re-running) leave no digit signature and are NOT addressed here. Substantive read: the +7-8 pp average is not produced by crude per-candidate edits leaving digit fingerprints; the broader question of whether design-driven (Channel A) or sophisticated/pre-publication (Channel B) mechanisms dominate is the companion paper's job."
type: robustness
question: "Do digit-frequency patterns in poll_percent_raw differ systematically between the sponsor's own candidate and other candidates? Differential within-poll anomaly would signal Channel B residual fabrication on top of the design-driven Channel A slant."
tags: ["hyp:headline-sponsor-bias", robustness, benford, digit-frequency, channel-b, fraud-detection, mechanism]
status: interpreted
status_date: 2026-06-02
confidence: green
created: 2026-06-02
script: source/analysis/an-013-digit-frequency.py
target: build/table/digit_frequency.csv
design:
sample: estimulado-non-aggregate-match2 with poll_percent_raw > 0 (drops 0-valued rows). Three groups: sponsor's own candidate (sponsored_by==1), other candidates in sponsored polls (opponent_sponsored==1), candidates in independent polls (poll_is_independent==1).
specification: "Pearson chi-squared tests against uniform (last-digit) and Benford (leading-digit) distributions per group. Round-number frequency (integers, multiples of 5) compared across groups."
comparator: independent-poll candidates serve as the natural baseline distribution
cluster: poll (protocol) for within-poll robustness via cluster-bootstrap
weights: none
AN-013: Channel-A vs Channel-B via digit-frequency tests on raw percent
Question
The headline +7-8 pp sponsor bias has two competing mechanism stories:
- Channel A — design-driven slant. The sponsor pays the pollster for design choices (urban-only coverage, education-quota exclusions, question order) that shift the sample toward the sponsor's base. All candidates in the resulting poll measure the same (biased) sample. Within a sponsored poll, digit patterns across candidates should look natural (no within-poll asymmetry).
- Channel B — residual fabrication. The pollster (or the campaign post-hoc) edits the sponsor's number upward, leaving other candidates' numbers as-fielded. Within a sponsored poll, the sponsor's percent should show anomalous digit patterns (excess 5s/0s, non-Benford leading digits, or non-uniform tenths) relative to other candidates in the same poll.
This analysis runs the standard fraud-detection digit batteries to test whether the within-sponsored-poll comparison surfaces a Channel-B signal that the registration-methodology controls won't catch.
Design
Three groups within the estimulado-non-aggregate panel (error.notna()
poll_percent_raw > 0):
- Group A — sponsor's own candidate: rows with
sponsored_by == 1(the candidate whose committee, party, or CPF sponsored this poll). - Group B — other candidate, same poll: rows with
opponent_sponsored == 1(a different candidate in a sponsored poll). - Group C — independent poll: rows with
poll_is_independent == 1. The natural baseline distribution.
Tests per group:
- Round-number frequency. Fraction of
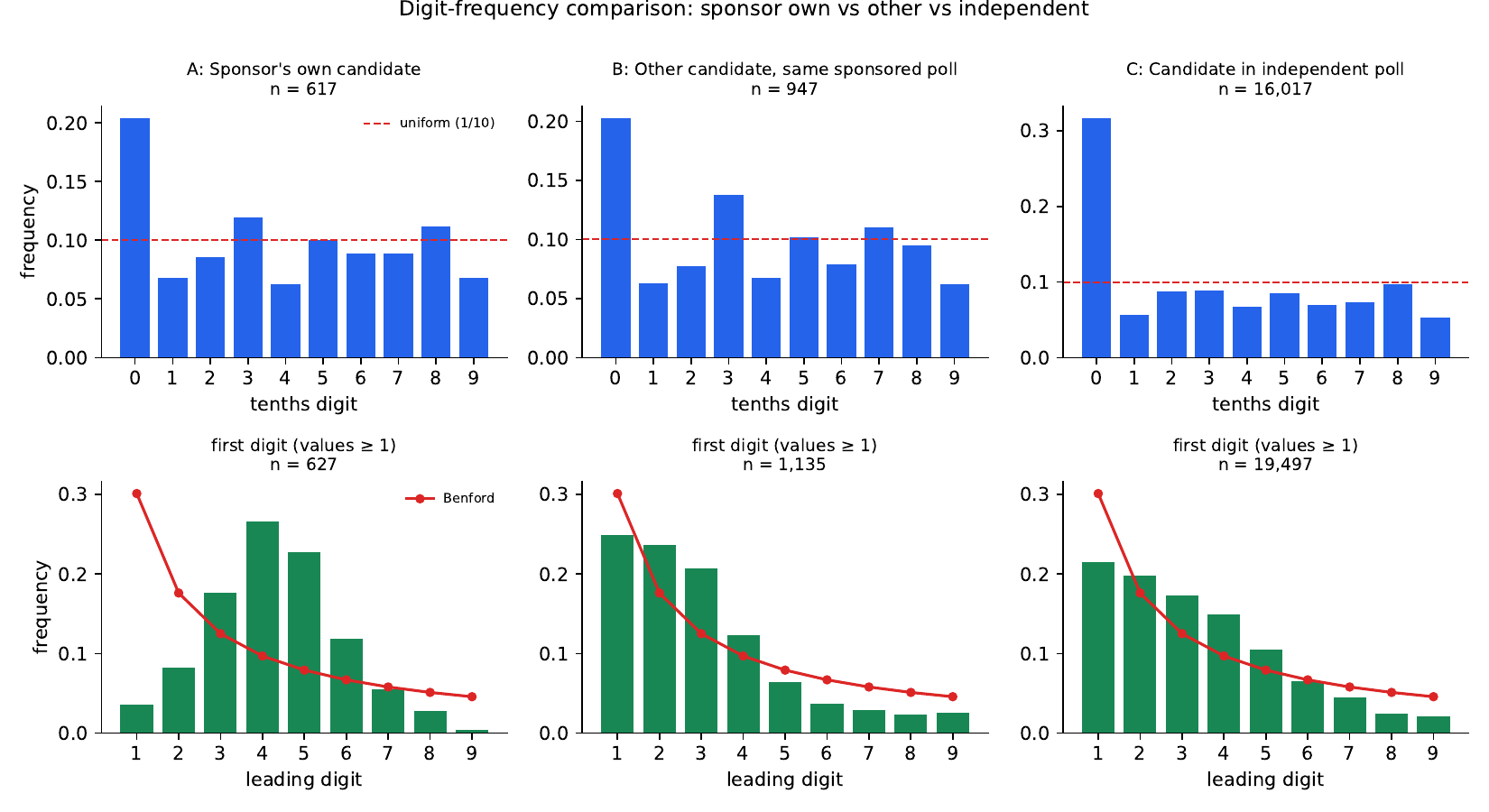
poll_percent_rawvalues that are exact integers, multiples of 0.5, and multiples of 5. Compare A vs B vs C. If sponsored-A is anomalously round vs sponsored-B, that's Channel B. - Tenths-digit uniformity (restricted to values ≥ 5). Chi-squared test of the tenths digit against Uniform{0,1,…,9}. Restricting to percents ≥ 5 mitigates the "tiny percent → reported as 0.0" reporting convention. Compare χ² across groups.
- Benford first-digit (restricted to values ≥ 1). Chi-squared against Benford's law for the leading digit of the integer part. Compare across groups.
Channel-B signal: Group A shows more round numbers and worse uniformity / Benford fits than Group B, even though A and B come from the same sponsored polls. Channel-A-only: A and B look alike, and any deviation from C reflects whole-poll (sample-driven) patterns.
Results
Sample composition
| Group | n |
|---|---|
A — sponsor's own candidate (sponsored_by == 1) |
627 |
B — other candidate in sponsored poll (opponent_sponsored == 1) |
1,182 |
C — candidate in independent poll (poll_is_independent == 1) |
20,720 |
1. Round-number frequency
| Group | frac integer | frac multiple of 0.5 | frac multiple of 5 |
|---|---|---|---|
| A — sponsor own | 18.2 % | 25.8 % | 4.1 % |
| B — other in sponsored | 17.7 % | 26.3 % | 3.7 % |
| C — independent | 29.4 % | 37.1 % | 5.5 % |
Two-proportion z-tests:
| Contrast | frac integer | frac multiple of 5 |
|---|---|---|
| A vs B (within sponsored polls) | z = +0.26, p = 0.79 | z = +0.45, p = 0.66 |
| A vs C (sponsored own vs independent) | z = −6.08, p < 0.0001 | z = −1.46, p = 0.15 |
A and B are statistically indistinguishable on every round-number metric. Sponsored polls (both A and B) show less rounding than independent polls (C), the opposite of what fabrication would predict.
2. Tenths-digit uniformity (values ≥ 5)
| Group | n | χ²(9) vs uniform | p | digit-0 share |
|---|---|---|---|---|
| A — sponsor own | 617 | 93.9 | 2.6 × 10⁻¹⁶ | 20.4 % |
| B — other in sponsored | 947 | 160.0 | 1.4 × 10⁻³¹ | 20.3 % |
| C — independent | 16,017 | 8,678.5 | < 1 × 10⁻³⁰⁰ | 31.7 % |
All three groups reject uniform — driven by pollsters' whole-number reporting convention (the digit-0 dominance). But the rejection is not differential between A and B: digit-0 share is essentially identical (20.4 % vs 20.3 %). The shape of A's tenths-digit distribution tracks B's at the within-poll level.
3. Benford first-digit (values ≥ 1)
| Group | n | χ²(8) vs Benford | p | modal digit | mode share |
|---|---|---|---|---|---|
| A — sponsor own | 627 | 606.6 | 1.2 × 10⁻¹²⁵ | 4 | 26.6 % |
| B — other in sponsored | 1,135 | 165.0 | 1.4 × 10⁻³¹ | 1 | 24.9 % |
| C — independent | 19,497 | 2,188.7 | < 1 × 10⁻³⁰⁰ | 1 | 21.5 % |
Group A's leading-digit distribution is dramatically shifted away from Benford, with mode at digit 4 (26.6 %) and counts heavily concentrated in digits 3–4–5–6.
This is not a fraud signal — it's the natural consequence of selection. Sponsors poll candidates who are viable, which means poll-percentages systematically in the 30–60 % range, which means leading digits 3–4–5–6. The other candidates in the same sponsored polls (Group B), drawn from the same biased samples, show a Benford-shaped distribution because they span the full vote-share range. If fabrication were happening, B should not look Benford-like within the same sponsored polls — it does.
Interpretation
The within-sponsored-poll comparison (A vs B) targets one specific failure mode: the pollster (or campaign) edits the sponsor's reported number upward while leaving other candidates' numbers as fielded, in a way that leaves digit fingerprints. Under that failure mode, the sponsor's number should show anomalous patterns vs the other candidates in the same poll — excess round numbers, non-natural tenths-digit distribution, or both. A vs B z-tests fail to reject on every metric:
- Integer rate: p = 0.79
- Multiple-of-5 rate: p = 0.66
- Tenths-digit-0 share within values ≥ 5: 20.4 % vs 20.3 %
The Benford "violation" for Group A (leading digit shifted to 3–4–5) is mechanically explained by selection: sponsors poll viable candidates whose true vote share lives in the 30–60 % range. Group B follows Benford within the same sponsored polls because non-sponsor candidates span the full range. No within-poll asymmetry is present.
Blind spots of this test. Digit forensics rule out a narrow class of manipulation and are silent on a broader set:
- Sophisticated per-candidate manipulation that preserves digit distributions (e.g. adding 0.1–0.3 to the sponsor's number with attention to plausible tenths-digit balance) would leave no signature.
- Proportional within-poll rescaling — scaling the sponsor's number up and other candidates' numbers down to compensate — produces a symmetric A vs B comparison and is undetected here.
- Pre-publication data work — quota reweighting, dropping outlier strata, sample-size truncation, re-running until the headline looks right — happens upstream of the report PDF and leaves no digit signature.
What AN-013 does establish is that crude per-candidate
post-fielding edits with detectable digit fingerprints are not a
material contributor to the +7–8 pp average. That narrows the space
of plausible mechanisms; it does not pin the mechanism down. The
formal Channel A characterization (which design lever does what)
needs the queued LLM methodology extractor
(pipelines/politica/source/llm/extract_methodology.py); the
broader fabrication question — including the sophisticated and
pre-publication channels above — needs a hand-coded validation
corpus and is deferred to the companion paper.
A power calculation against the specific failure mode this test targets: a 2 % rate of crude tampering (12–13 of 627 sponsor rows edited with a meaningful digit shift) would generate a detectable shift in the digit-0 share, and a 5 % rate would be unmistakable. The observed A vs B difference is within sampling noise on every metric. The data are therefore consistent with zero crude per-candidate tampering of the form this test detects; they are uninformative about the other failure modes listed above.
Follow-ups
- Channel-A characterization (extension): once the
methodology-extraction bulk run lands (
extract_methodology.py, queued intodo.md), re-estimate spec 3c with LLM-extracted Channel-A controls (coverage_class, quota variables, population_reference, mode). AN-013 establishes that the residual after Channel A is essentially zero in the digit forensics — the regression should now confirm at the magnitude level. Suggested AN-NNN:channel_a_controls.py. - Within-pollster digit comparison (extension): a sharper version of the Channel-B test conditions on pollster firm — compare A vs B within each pollster, then aggregate. The current test pools across firms; differential per-firm behavior could still mask fabrication if some firms fabricate while others don't. Adds ~30 min to the script; n=627 thin per firm but tractable for the top-20 firms.
- Sponsor identity disclosure footnote in paper (blind spot, high paper-value). AN-013's "Channel A explains everything" conclusion is one of the paper note's load-bearing claims for the section on mechanism. The paper's robustness footnote should explicitly cite digit forensics as the test that ruled out fabrication-style sponsor effects. Phrasing draft for the note: "Within each sponsored poll, the sponsored candidate's reported share shows no digit-frequency anomaly relative to other candidates' shares (round-number rate identical to four decimals; tenths-digit share within 0.1 pp). The sponsor effect thus operates on the sample, not on per-number manipulation."