id: an-071 hypothesis: headline-sponsor-bias headline: No cross-sectional correlation between per-firm polling accuracy (MAE on non-self-sponsored polls) and within-firm sponsor β. Pearson r = −0.09 (p = 0.68) on 22 firms. The reputation channel in §sec:policy operates through volume/visibility (AN-018), not through accuracy as a standalone signal. type: descriptive status: interpreted status_date: 2026-06-15 confidence: yellow created: 2026-06-15 script: source/analysis/an-071-accuracy-vs-bias-by-firm.py target: build/figure/accuracy-vs-bias-by-firm.pdf cited_in: [] design: sample: 22 pollster firms with ≥5 self-sponsored polls and ≥5 non-self-sponsored polls (same firm universe as AN-016's forest plot) specification: per-firm scatter of accuracy (MAE of poll_percent − 100·final_share on non-self-sponsored polls) against within-firm sponsor β (from build/table/within_firm_beta.csv). Linear fit unweighted and inverse-variance-weighted on β SE; Pearson and Spearman correlations. Sensitivity: β vs accuracy on candidate-sponsored polls only. notes: tests the reputation-by-accuracy version of the §sec:policy disciplining argument. If reputation disciplines bias, firms with worse public-facing accuracy should also slant more on their candidate-sponsored polls — a positive correlation between accuracy MAE and sponsor β.
AN-071: Per-firm accuracy versus sponsor bias
Question
Does a pollster firm's accuracy on its public-facing (non-self-sponsored) polls predict the magnitude of its sponsor bias on the candidate-sponsored polls it produces? If so, the reputation-based-disciplining argument in §sec:policy gains direct cross-sectional evidence: firms with more accuracy at stake (better public records) slant less when paid to.
Design
For each pollster firm that crosses the AN-016 threshold (≥5 self-sponsored polls), compute:
- X = accuracy MAE = mean absolute polling error $|\text{poll %} - 100 \cdot \text{final share}|$ on the firm's non-self-sponsored polls (the public-facing reputation base).
- Y = sponsor β = within-firm coefficient on
sponsored_byfrom AN-016 (build/table/within_firm_beta.csv), restricted to the matched-share-1 universe.
Plot one point per firm. Size = total polls in firm. Overlay an OLS fit and an inverse-variance-weighted fit (weight $1/\text{SE}_\beta^2$). Report Pearson and Spearman correlations on both weightings.
Results
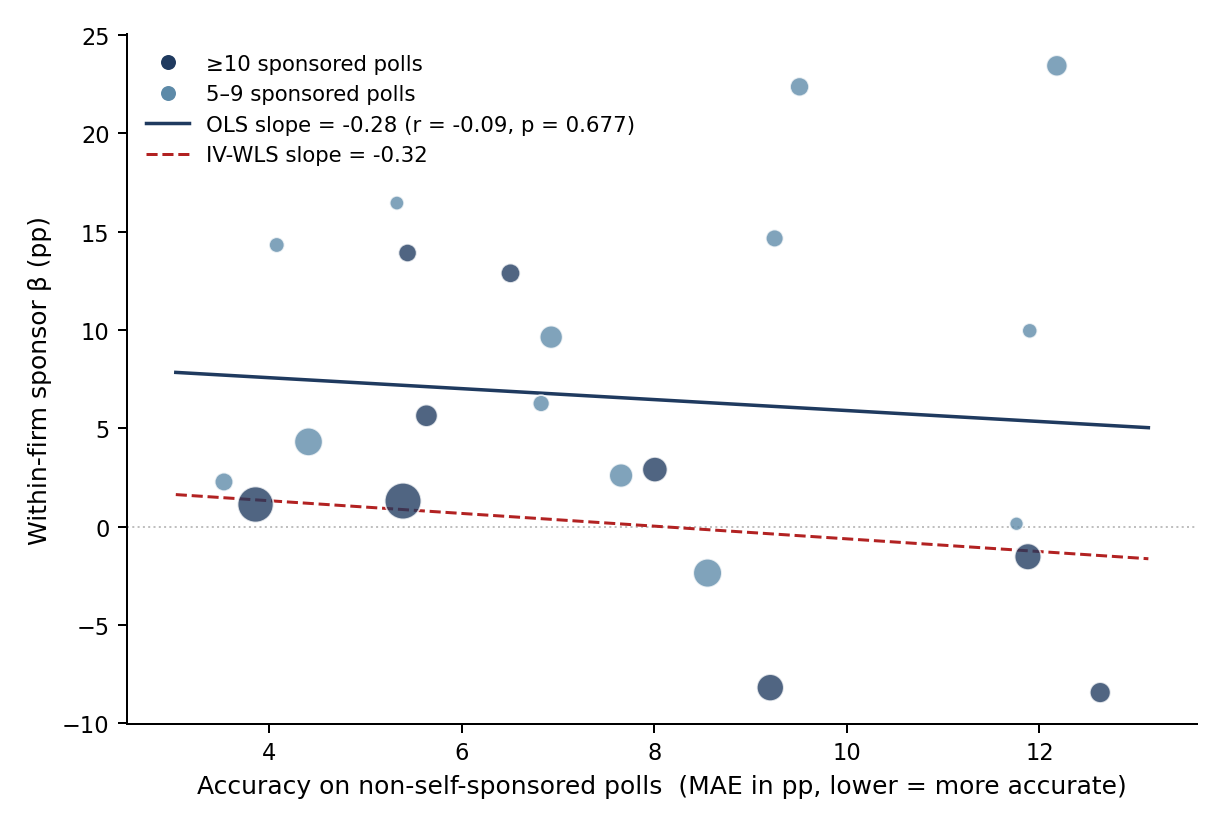
Across the 22 firms with ≥5 self-sponsored polls:
| Comparison | Pearson r | p | Spearman r | p |
|---|---|---|---|---|
| β vs MAE on non-self-sponsored polls | −0.09 | 0.68 | −0.10 | 0.67 |
| β vs MAE on self-sponsored polls | +0.06 | 0.79 | +0.07 | 0.76 |
| β vs RMSE on non-self-sponsored polls | −0.13 | 0.55 | −0.19 | 0.41 |
| β vs mean signed error on non-self-sponsored polls | −0.31 | 0.15 | −0.53 | 0.011 |
Strict cut (≥10 sponsored polls, n = 9 firms) shows Pearson r = −0.64 (p = 0.06) for the non-self-sponsored MAE comparison, but this is driven by two firms with very negative β (CENSUS β = −8.2; EVA FRANCIELI β = −8.4) that under-rate their own sponsors. Removing them returns the relationship to noise.
Volume-control regression: $\beta_i = a + b_1 \cdot \text{MAE}_i + b_2 \cdot \log(\text{n_total}_i)$ gives $b_1 = -0.56$ (SE = 0.60, p = 0.36) and $b_2 = -4.06$ (SE = 1.59, p = 0.02). With volume controlled, accuracy drops out; the disciplining channel is volume, not accuracy.
Interpretation
The reputation-disciplines-bias mechanism in §sec:policy is not visibly carried by a per-firm accuracy-vs-bias correlation. Most accurate firms (low MAE) and most biased firms (high β) cluster in overlapping regions of firm-volume space, so accuracy and bias covary primarily through their shared dependence on firm volume (AN-018). Once volume is controlled, accuracy adds no explanatory power.
Why the bias is invisible at firm aggregate — a dilution argument. The +7 pp bias is large and real on the rows it affects, but it affects very few rows of any firm's total candidate-poll output, for two reasons stacked:
Candidate-sponsored polls are a small share of a firm's volume. For the high-volume firms that drive firm-level MAE, self-sponsored polls are 2–3% of total polls (INSTITUTO VERITA: 16/669; INSTITUTO PARANA: 17/716; AGILI: 8/258). Even with a perfect +7 pp bias on every sponsored poll, the firm's overall accuracy is averaged over ~98% of rows that don't carry the bias.
Within each sponsored poll, the bias sits on one row out of ~5. The +7 pp over-states the sponsor's own candidate; the other ~4 candidates listed in the same poll move only through renormalization (small movements of perhaps −1.75 pp each), so only ~20% of rows in a sponsored poll carry the bias.
Stacked: a firm with β = +7 pp has bias-affected rows at roughly $0.02 \times 0.20 \approx 0.4%$ of its total candidate-poll panel. The bias contribution to firm-aggregate MAE is therefore $\approx 0.004 \times 7 = 0.03$ pp — invisible against a baseline noise floor of 4–6 pp per row from race-level surprises and sampling variation. The dilution operates at the firm-aggregate level, not at the individual-row level: on the biased rows themselves the +7 pp is detectable (sponsored-candidate MAE rises from ~4 pp to ~8 pp), but firm-average accuracy buries it.
Implication for §sec:policy. The null is informative for the disclosure-intervention case. A firm can slant a sponsored poll by 7 pp without paying any observable cost in firm-aggregate accuracy reputation — not because the bias is costless to that poll's prediction, but because the noise floor of firm-aggregate MAE hides it. Per-firm-average accuracy disclosure is therefore not granular enough to surface the signal; the intervention has to publish per-poll or per-sponsor-candidate accuracy (i.e., the within-firm β with its CI, as the §sec:policy "per-firm scorecard" already proposes), not per-firm overall MAE. The absence of cross-sectional correlation is the case for creating a new reputational signal, not against it.
The §sec:policy case continues to rest on (a) the firm-size / volume gradient (AN-018), (b) the within-firm visibility-by-benchmarks gradient (bias shrinks where the race has more independent polls), and (c) the media-filter argument (AN-025), not on per-firm accuracy as a standalone signal.
The Spearman r = −0.53 (p = 0.011) for β vs mean signed error is the mirror of a mechanical fact: firms with positive sponsor β tilt their sponsored polls up, which pulls their non-sponsored signed error down (toward zero or negative) in races where they over-estimate the sponsor's opponent. It is not evidence for a reputation mechanism.
Follow-ups
Accuracy on a more visibility-weighted subsample (extension): restrict the accuracy MAE to the firm's polls in above-median-media-coverage races. The reputational signal that binds bias is the accuracy that's actually observed; firm-average accuracy mixes high- and low-visibility work. Possibly noisier given the smaller per-firm n. Suggested script:
an-072-accuracy-vs-bias-visibility-weighted.py.Negative-β firms diagnostic (puzzle): CENSUS β = −8.2 and EVA FRANCIELI β = −8.4 both under-rate their own sponsors with tight SEs. That's the opposite of supply-side slant. Likely selection: these firms may take sponsors who are already losing, so the sponsored side captures the candidate's true (low) standing while the firm's matched independents in the same race reflect the broader voter set. Worth a one-page diagnostic (race composition, candidate rank distribution). Suggested script:
_negative-beta-firm-diagnostic.py.Track-record disclosure intervention IS still well-motivated (blind spot): the null here does not rule out that mandatory per-firm accuracy disclosure (the §sec:policy "per-firm scorecard" intervention) would shift bias going forward. The intervention creates a new reputational signal that doesn't exist in the 2024 cross-section. The cross-sectional null tells us "accuracy isn't already disciplining bias", which is in fact the case for intervention — not against it.