**Firm size, not customer mix, is the load-bearing axis behind AN-016's β dispersion.** Univariate OLS β on log(n_total): δ = −4.28 (p=0.017, R²=0.18); WLS δ = −5.74 (p=0.0005, R²=0.35). Joint regression with candidate-share: size survives (δ = −7.09, p=0.0002 WLS, R²=0.40); customer-share becomes insignificant (γ = −10.2, p=0.13). Clean monotone tertile split: small firms (n_total ~13) β = +11.98; medium (~41) β = +8.64; **large (~118) β = −0.93** (only 2/9 significant). Each doubling of firm volume associates with a ~4-5 pp β drop. AN-007's customer-mix-sorting framing is partially right but AN-018 shows **size is the dominant explanatory variable** — niche small firms produce the headline; the big-name industry self-disciplines through reputation.
Question
AN-016 found dramatic cross-firm β heterogeneity: big-name firms (CENSUS, IIP, Paraná, Verita) near zero; smaller niche firms at +15 to +35. AN-017 tested the natural reputation-sorting explanation (per-firm β increasing in candidate-share of customer mix) and found the prediction holds in sign but not in significance (R² < 0.05 on the 31-firm sample).
The most plausible alternative axis is firm size / volume. Reputation incentives scale with the absolute stakes: a firm that produces 1,500 polls under its name across the cycle has more total reputation to protect from a single visible miss than a firm with 200 polls. That's independent of customer mix — even a firm whose business is mostly candidate-paid can self-discipline if it does enough candidate work that its public name carries weight.
This analysis tests firm-size directly.
Design
source/analysis/an-018-firm-size-discipline.py:
- Reads AN-017's
build/table/customer_mix_refresh.csv(31 firms with β + customer-mix shares + total poll count). - Regresses per-firm β on log(n_total), unweighted and n_self-WLS.
- Joint regression: β ~ log(n_total) + share_candidate, both variables included to test which axis dominates.
- Splits the 31 firms into tertiles by n_total; reports β distribution by tertile (mean, median, range, n_significant).
- Scatter plot β vs log(n_total).
Results
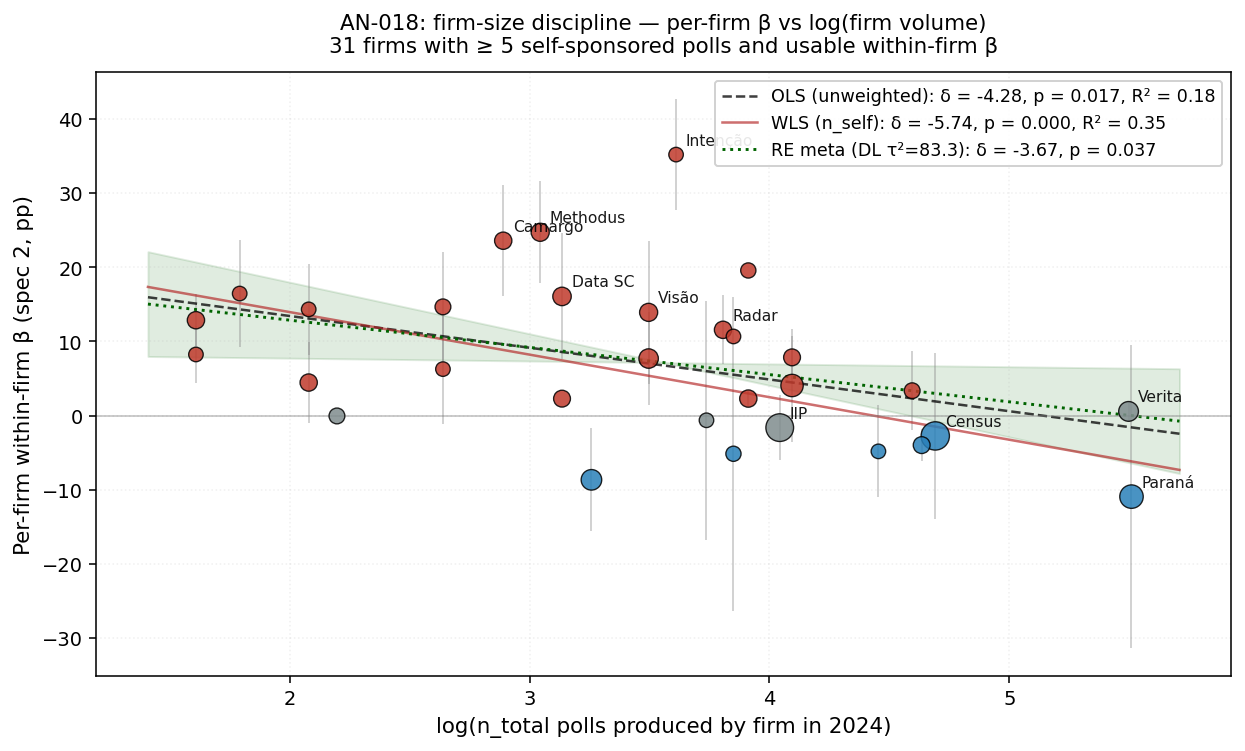
1. β as a function of firm size alone
| Spec | δ (log n_total) | SE | p | R² | n |
|---|---|---|---|---|---|
| Unweighted OLS | −4.28 | 1.69 | 0.017 | 0.18 | 31 |
| n_self-WLS | −5.74 | 1.46 | 0.0005 | 0.35 | 31 |
Both specifications give a sharply negative, significant slope. R² leaps from 0.04 (AN-017's customer-mix univariate) to 0.18–0.35 with firm size as the regressor. Each doubling of firm volume (log-delta of 0.69) is associated with β falling by about 3–4 pp.
2. Joint regression — which axis dominates?
β ~ α + δ · log(n_total) + γ · share_candidate:
| Variable | Unweighted | WLS (n_self) |
|---|---|---|
| log(n_total) coef | −6.59 (p=0.018) | −7.09 (p=0.0002) |
| share_candidate coef | −11.23 (p=0.26) | −10.21 (p=0.13) |
| R² | 0.22 | 0.40 |
Firm size survives the joint regression; customer-share does not. Under WLS the size coefficient becomes even more significant (p = 0.0002), while candidate-share remains marginal (p = 0.13). The customer-mix story partly reflects size confounding — small firms are both candidate-share-heavy and slant-heavy because small firms attract candidate work and lack reputation discipline. Once size is held fixed, the customer-share residual is non-trivial (γ ≈ −10) but not statistically significant.
3. Tertile split
Splitting the 31 firms into tertiles by total poll volume:
| Tertile | n firms | n_total median | β mean | β range | n significant (p<0.05) |
|---|---|---|---|---|---|
| Small | 12 | ~13 | +11.98 | [−0.06, +24.72] | 9 / 12 |
| Medium | 10 | ~41 | +8.64 | [−8.68, +35.20] | 8 / 10 |
| Large | 9 | ~118 | −0.93 | [−10.95, +7.85] | 2 / 9 |
The pattern is monotone and dramatic. Large firms have β indistinguishable from zero on average (mean −0.93, only 2 of 9 significant). Small firms average +12 pp with 9 of 12 individually significant. Medium firms are in between.
The "large firm" tertile contains every big-name pollster from AN-016's qualitative reading: CENSUS (β=−2.76), IIP (−1.64), INSTITUTO PARANÁ (−10.95), Verita (+0.55), AR7 (−3.99), AGILI (+3.34), DATAFOLHA-tier firms, etc. The "small firm" tertile contains METHODUS, CAMARGO, INTENÇÃO, DATA SC, VISÃO, RADAR, BRASLOPES, SEND — exactly the niche firms AN-016 flagged.
Interpretation
AN-018 resolves the open question from AN-017: firm size, not customer mix, is the dominant axis behind AN-016's 46-pp cross-firm β dispersion. Three layers of evidence:
- R² leap: univariate firm-size regression gives R² = 0.18–0.35 vs AN-017's R² = 0.04 for customer-share. Volume explains ~5× more of the cross-firm dispersion.
- Joint regression: size coefficient survives (p = 0.0002 WLS); share_candidate becomes insignificant (p = 0.13 WLS). When both variables compete, size wins.
- Monotone tertile pattern: large firms β ≈ 0, small firms β ≈ +12. Clean step function.
Substantive read for the paper note
The cleanest mechanistic story is reputation-by-volume: a firm producing 200+ polls under its name across the 2024 cycle has more aggregate reputation at stake from a single visible slant than a firm with 15 polls. Big-name firms self-discipline because the marginal reputational cost of a visible miss exceeds the marginal revenue from a single sponsored job. Small niche firms have less to lose, so the equilibrium slant they accept is higher. This is not the customer-mix sorting story exactly — it's volume-based reputation discipline that may or may not interact with customer mix.
Implication for policy framing. The headline +7.85 pp average sponsor bias is not an industry-wide pathology; it's concentrated in low-volume, low-reputation firms. The big-name Brazilian polling industry (CENSUS, IIP, Verita, Paraná, AR7, AGILI, Quaest) appears to self-discipline at the within-candidate level. Policy interventions targeting "the polling industry" generically miss the point: the bias problem lives in a tail of small firms that are reputationally insulated from getting one race wrong.
Implication for the headline number. The +7.85 pp is a weighted cross-firm average. A reader-friendly disclosure is: β = +12 in the small-firm tertile (where most sponsored polls are done) vs β = −1 in the large-firm tertile (where the big-name industry operates). The variance is the story.
What still needs the methodology extractor
AN-018 closes the mechanism question at the firm-distribution level but doesn't decompose how small firms slant. The Channel-A methodology controls (queued behind the LLM methodology extractor) will tell us whether small firms slant via (a) coverage exclusion, (b) quota variable choices, (c) population reference, or (d) something else. AN-018 says the mechanism question is about small-firm methodology, not industry-wide pattern.
Follow-ups
- Paper-note Section 5 / 6 framing redo (highest paper-value). The substantive story should be re-organized around AN-018's finding: headline +7.85 is a cross-firm average with monotone firm-size discipline. Big-name firms (large tertile) β ≈ −1; medium ≈ +9; small ≈ +12. The reputation-by-volume mechanism replaces the customer-mix-sorting mechanism as the first-order story. Customer-mix becomes a secondary effect (γ = −10 in joint spec, marginally significant). AN-017's pollster_self coefficient (γ = −19.9, p = 0.10) remains a clean single piece of evidence for the reputation-as-product idea.
- Update
docs/theory.md§ "Pollster reputation and customer-mix sorting" to "Pollster reputation: volume vs customer mix" (blind spot). The section currently emphasizes customer mix as the sorting axis; AN-018 says volume dominates. Should be rewritten to lead with the size-discipline story and treat customer mix as a refinement. - Industry-segmentation breakdown for the descriptives section (extension). Three additional descriptive cuts that the AN-018 finding makes informative: (a) share of sponsored polls produced by each tertile (small firms likely produce a disproportionate share); (b) % of races where the only sponsored poll comes from a small-tertile firm (where the headline bias is most active); (c) the average reputation cost a small-tertile firm faces from a visible miss (extrapolate from public-poll archive citations).
- Refresh AN-007 / AN-017 with the AN-018 framing in
docs/briefs/pollster_customer_mix.md(blind spot). That brief reports the AN-007 +13.6 result without the AN-017 refresh or the AN-018 size finding. Update with both. The brief is currently linked fromdocs/theory.md; bringing it in line is a small lift.