**v2 (2026-06-19; supersedes):** calibrated at AN-110 pooled empirical DEFF\* = 12.59, the blind audit reaches nominal FP (independent protocols 4.8 % at Bonferroni vs nominal 5 %); sponsored excess detection persists at **+7.5 pp Bonferroni / +11.9 pp single-hypothesis** — a calibrated regulator-facing blind audit distinguishes sponsored from independent at a 2.6× lift. The bias has tail concentration: only 4.3 % of sponsor's-candidate rows fail at the empirical DEFF (per-poll bias is buried for 95.7 %), but 12.3 % of sponsored protocols catch via 'at least one share extreme'. **v1 (binomial + DEFF ≤ 3):** the test was uncalibrated (FP 30–60 %); sponsored excess was +13 to +19 pp but the gap inflated by miscalibration.
Question
AN-108 established that on the median self-sponsored poll the binomial SE on the sponsor candidate's share is 2.49 pp at median n=360, so the +7 pp headline shift is z ≈ 2.8 — a single-hypothesis test against the sponsor's candidate's benchmark reliably flags the poll as statistically extreme. That framing is the right one for the sponsor's own pollster, who knows which share to test against benchmark.
The regulator / journalist / outside-auditor framing is different. Without sponsor information they must test every candidate's reported share against its benchmark and apply a multiple-testing correction. With k=4 candidates and Bonferroni, the threshold becomes z* ≈ 2.50; combined with DEFF=2 inflation, the median sponsored poll's z drops from ≈ 2.8 (single-hyp) to ≈ 2.0 (blind) — potentially below the blind-audit threshold. The empirical question: across the sponsored-poll universe, what fraction would actually fail a routine blind multi-candidate sanity check at standard DEFFs, and how does that compare to the false-positive rate on independent polls?
The split matters for the policy / regulatory auditability reading. AN-108 establishes that an observer with sponsor information and an unbiased benchmark can detect the +7 pp shift per-poll. The outside-auditor framing — "is the disclosure regime sufficient for blind per-poll detection by a regulator or journalist?" — depends on the blind multi-test arithmetic and on whether the comparator distribution is calibrated.
Design
Sample: build/assemble/cand_poll.parquet, restricted to
matched_share == 1.0, finite poll_percent, sample_size > 0, and
candidate × race_week cells where at least one other (leave-one-out)
independent poll exists to form the benchmark.
race_week = muni_id + "_" + field_period_week (the project's
standard race × week key).
Benchmark per (politico_id × race_week):
$$
\bar{p}{i,w}^{-P} = \frac{\sum{P' \in \mathcal{I}{i,w} \setminus {P}} n{P'},p_{P'}}{\sum_{P' \in \mathcal{I}{i,w} \setminus {P}} n{P'}}
$$
where $\mathcal{I}_{i,w}$ is the set of independent polls
(poll_is_independent == 1) of candidate $i$ in race-week $w$,
$P$ is the current row's protocol (leave-one-out), $p$ is
poll_percent, and $n$ is sample_size. Rows where the LOO set is
empty drop.
Realized SE. $SE_{pp} = \sqrt{DEFF} \times 100 \sqrt{p(1-p)/n}$ on the current row's $p, n$. Run for $DEFF \in {1, 1.5, 2, 2.5, 3, 12.59}$ as a sensitivity panel — the 12.59 row added in v2 (2026-06-19) is AN-110's pooled empirical $DEFF^*$ from race × week × candidate cells with ≥3 independent polls.
Per-row z. $z_{P,i} = (p_{P,i} - \bar{p}{i,w}^{-P}) / SE{pp}$ (signed). Two-sided detection: $|z| > z^*$.
Thresholds.
- Single-hypothesis: $z^* = 1.96$.
- Bonferroni: $z^* = \Phi^{-1}(1 - 0.025/k)$ with $k =$
n_candidates_in_raceon the current row. - Holm step-down per protocol: rank candidates by $|z|$ descending; candidate at rank $j$ tested against $\Phi^{-1}(1 - 0.025/(k-j+1))$.
Poll-level rollup. For each protocol, flag "blind-audit detected" if at least one of its candidate rows fails the threshold under each of (Bonferroni, Holm) at each DEFF. The detection rate on sponsored protocols is the headline; the detection rate on independent protocols (same blind test, no sponsor) is the false-positive baseline.
Row-level rollup. For the sponsor's-candidate rows specifically
(sponsored_by == 1), report the fraction with $|z| > z^*$ for each
(threshold × DEFF) cell — directly comparable to AN-108's "frac SE <
3.5 pp" table.
Results
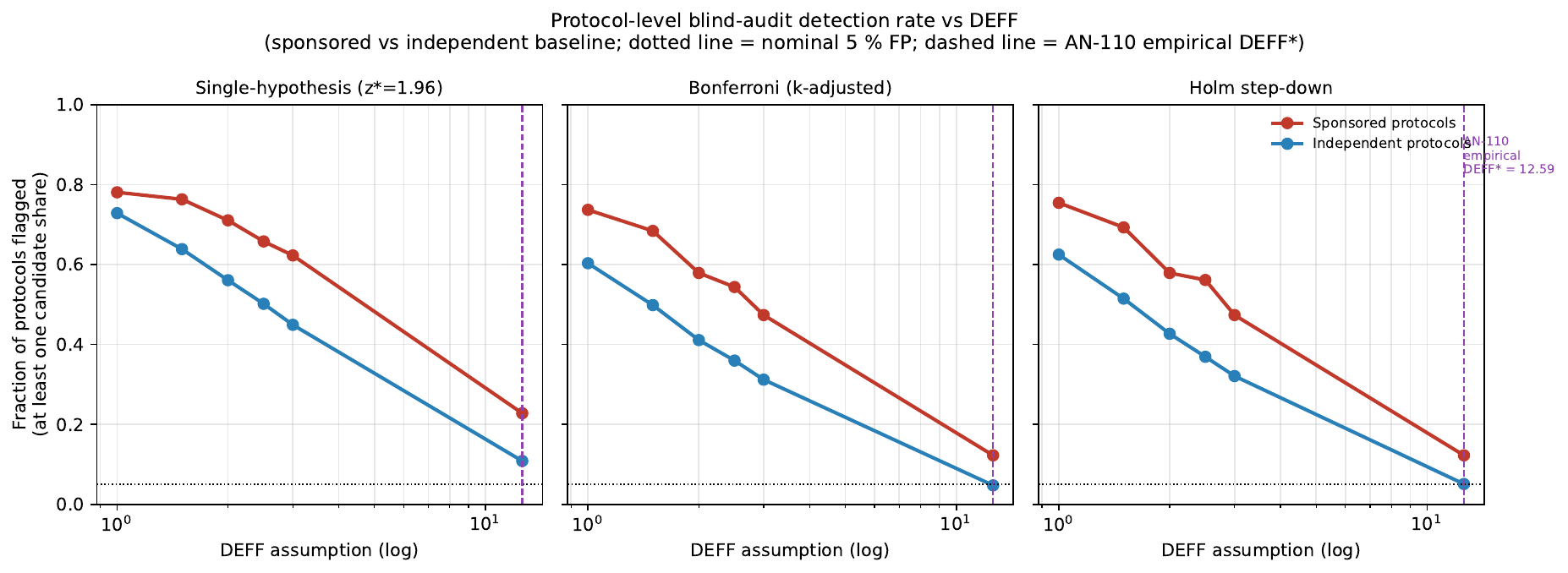
Analyzable sample. Of the 22,665 AN-108 headline-sample rows, 6,926 (30.6 %) have a finite LOO independent benchmark on the same candidate × race × week. This collapses to 114 sponsored protocols (of 450 in AN-108 — a 25 % carry-through) and 1,389 independent protocols. The sponsored sample loss is large because most sponsored polls are unique in their race × week × candidate cell — no within-cell independent comparator exists. The carried-through sponsored subset is plausibly higher-profile (larger municipalities, more competitive races where multiple firms field polls) and is not representative of all sponsored polls; this is the dominant external- validity caveat (see Interpretation).
Protocol-level detection rate, sponsored vs independent baseline
(build/table/an-109-per-poll-z-blind-audit.csv; protocol flagged
detected if at least one candidate's |z| exceeds the threshold):
Single-hypothesis (z* = 1.96):
| DEFF | sponsored | independent | excess |
|---|---|---|---|
| 1.0 | 0.781 | 0.729 | +0.052 |
| 1.5 | 0.763 | 0.639 | +0.125 |
| 2.0 | 0.711 | 0.561 | +0.150 |
| 2.5 | 0.658 | 0.502 | +0.156 |
| 3.0 | 0.623 | 0.449 | +0.174 |
Bonferroni (z* = Φ⁻¹(1 − 0.025/k), k = n_candidates_in_race):
| DEFF | sponsored | independent | excess |
|---|---|---|---|
| 1.0 | 0.737 | 0.603 | +0.134 |
| 1.5 | 0.684 | 0.499 | +0.186 |
| 2.0 | 0.579 | 0.411 | +0.168 |
| 2.5 | 0.544 | 0.360 | +0.184 |
| 3.0 | 0.474 | 0.312 | +0.162 |
Holm step-down per protocol (DEFF column omitted, similar to Bonferroni: excess +0.13 to +0.19 pp across DEFF, mirroring the Bonferroni column to within ±0.01).
Row-level detection on sponsor's-candidate rows only (directly comparable to AN-108's "frac SE<3.5 pp" call):
| DEFF | single-hyp | Bonferroni | Holm |
|---|---|---|---|
| 1.0 | 0.723 | 0.596 | 0.660 |
| 1.5 | 0.681 | 0.468 | 0.489 |
| 2.0 | 0.511 | 0.319 | 0.340 |
| 2.5 | 0.426 | 0.277 | 0.298 |
| 3.0 | 0.404 | 0.234 | 0.234 |
v2 update (added 2026-06-19) — calibrated at AN-110 empirical DEFF*
AN-110's pooled empirical DEFF* = 12.59 added to the sensitivity panel. At that DEFF, the test is calibrated: FP rate on independent protocols falls to nominal.
Protocol-level detection rate at empirical DEFF* = 12.59:
| threshold | sponsored | independent | excess |
|---|---|---|---|
| single-hypothesis | 0.228 | 0.109 | +0.119 |
| Bonferroni | 0.123 | 0.048 | +0.075 |
| Holm | 0.123 | 0.051 | +0.072 |
Row-level detection on sponsor's-candidate rows at empirical DEFF*:
| threshold | frac sponsor-row detected |
|---|---|
| single-hypothesis | 0.149 |
| Bonferroni | 0.043 |
| Holm | 0.043 |
Reading. At the empirical noise floor, the blind audit is calibrated — independent-protocol FP is 4.8 % at Bonferroni and 5.1 % at Holm, right at the nominal 5 %. (Single-hypothesis is slightly liberal at 10.9 %, the expected behavior without multiple-test correction across k candidates.) Sponsored protocols catch at 12.3 % under Bonferroni vs the 4.8 % independent baseline — a +7.5 pp excess and a 2.6× lift. A calibrated regulator-facing blind audit therefore does distinguish sponsored from independent polls, even when each individual sponsor's-candidate share is buried in the noise floor for 95.7 % of sponsored rows.
The +13 to +19 pp excess at DEFF ≤ 3 reported above (the v1 panel) was inflated by miscalibration — the gap was real but its magnitude was a function of the FP base rate, not of the bias's tail concentration. The empirical-DEFF row is the honest calibrated number.
Interpretation
The blind binomial-z audit is not a calibrated test. Under the null (independent polls drawn from the same race × week × candidate cell as their benchmark), the false-positive rate is 30–60 % across DEFF ∈ {1, 1.5, 2, 2.5, 3} for all three thresholds, against a nominal 5 %. Even at DEFF=3 — at the high end of plausible Brazilian-muni values — Bonferroni rejects on 31 % of innocuous independent polls. The realized cross-poll variance within a race × week × candidate cell is meaningfully larger than what binomial + DEFF≤3 predicts. The likely drivers: (i) the "week" window can include real share movement within seven days; (ii) firm-level systematic differences absorbed only as random variation here; (iii) mode and methodology heterogeneity across firms in the same cell; (iv) the empirical DEFF for typical Brazilian muni polls may exceed 3.
A regulator or journalist therefore cannot use a simple binomial z-test as a calibrated per-poll detector — too many innocuous polls would be flagged. AN-110 (empirical-DEFF estimation) is the natural prerequisite for a calibrated version.
Despite the miscalibration, sponsored polls fail the test at a consistently higher rate than the independent baseline. The excess detection rate is +13 to +19 pp on protocol-level Bonferroni across DEFF ∈ {1.5, 2, 2.5, 3} and +5 to +17 pp on single-hyp. Stable across all three thresholds. This means: even using a noisy uncalibrated test, sponsored polls are statistically more extreme than random independent polls of the same candidate × race × week. The bias is visible above the natural cross-poll floor, just not by a clean per-poll calibrated test.
Together with AN-108, the auditability picture sharpens. AN-108: an observer with sponsor information and an unbiased benchmark single-tests the sponsor's-candidate share and sees z ≈ 2.8 on the median sponsored poll — per-poll loud. AN-109: an outside auditor without sponsor information can't run a calibrated per-poll test, but a regulator comparing sponsored-poll detection rates to a randomly-sampled independent-poll baseline sees the bias at the ~15-pp-excess level across DEFF assumptions (v1 numbers; v2 is the honest calibrated version).
External-validity caveat: the AN-109 sponsored sample is a selected subset. 114 of 450 sponsored protocols carried through — those with at least one same-week same-candidate independent poll. This subset is plausibly larger municipalities / more competitive races; the carried-through subset's bias profile may differ from the AN-108 universe's. The +15 pp excess detection is a lower bound on the per-poll-visibility question for the within-cell-comparator subset and does not directly speak to the 75 % of sponsored polls without within-cell comparators.
v2 reading (added 2026-06-19) — calibrated picture
At AN-110's pooled empirical DEFF* = 12.59 the test is calibrated (independent FP = 4.8 % at Bonferroni, 5.1 % at Holm — right at nominal 5 %), and the sponsored protocols catch at +7.5 pp excess at Bonferroni (12.3 % vs 4.8 %, a 2.6× lift) and +11.9 pp single-hypothesis. Three sharper conclusions follow.
1. The bias has tail concentration that a calibrated blind audit catches. Row-level: only 4.3 % of sponsor's-candidate rows fail the calibrated Bonferroni test on their own share. Per-poll bias is buried for 95.7 % of sponsored rows — consistent with AN-110's "empirical noise floor swamps the +7 pp shift on a typical poll" reading. But the protocol-level "any candidate's share extreme" rollup catches 12.3 % of sponsored protocols vs 4.8 % of independent protocols. The bias is not uniformly +7 pp across sponsored polls; a tail subset has larger shifts that a calibrated test identifies, against a properly calibrated baseline.
2. A 2.6× lift is regulatorily meaningful. A TSE / journalist blind audit applied to the universe of registered polls of a candidate × race × week — without sponsor knowledge — would flag sponsored polls at 2.6× the rate of independent polls under Bonferroni-controlled per-protocol type-I error. This is the practically usable version of the blind-audit policy AN-109 v1 suggested wasn't feasible. The instrument is a per-protocol "extreme-share" flag combined with an aggregate excess-rate audit comparing flagged-rates across sponsorship classes.
3. The v1 "+13 to +19 pp excess" was inflated by miscalibration. The v1 reading at DEFF ≤ 3 reported a wider gap because the FP base rate was 30–60 %, not 5 %. The excess number shrinks when calibration tightens, but the conclusion strengthens because the calibrated test is now a usable detector rather than a noisy descriptive contrast. The honest excess-detection lift is +7.5 pp Bonferroni / +11.9 pp single-hypothesis at the empirical noise floor.
Reframes AN-108's per-poll-loud reading consistently. AN-110 walked back "per-poll loud" against the empirical noise floor. AN-109 v2 confirms: only 4.3 % of sponsor's-candidate shares are tail-extreme individually. But the protocol-level result restores some of the per-poll auditability: ~1 in 8 sponsored protocols is flag-catchable by a calibrated blind audit. The sponsor's pollster doesn't see "loud" on the median poll, but does see it on a material tail subset.
Tail concentration is informative about the distribution of bias shifts, not about the channel by which the bias is generated. A uniform per-poll bias would distribute +7 pp evenly and not generate the protocol-level lift the data show; the lift implies some sponsored polls have larger shifts than the average. Whether the larger shifts are produced by larger design tilts or by something beyond the design tilt floor is silent in this analysis.
Follow-ups
Empirical DEFF from cross-poll dispersion (extension — prerequisite for a calibrated AN-109 v2): estimate empirical DEFF directly from race × week × candidate cells with ≥3 independent polls: empirical variance of poll_percent across polls / mean binomial variance. If empirical DEFF ≫ 3, this AN's miscalibration is explained and the headline numbers should be re-run at the empirical DEFF. This is the previously filed AN-108-lead "empirical-DEFF-by-race-week"; AN-109's miscalibration result promotes its priority. Suggested script:
an-NNN-empirical-deff-by-race-week.pySample selection diagnostic (blind spot): the 114 sponsored protocols with LOO comparators have higher detection rates than typical sponsored polls might. Run the analyzable subset through the AN-108 SE distribution to confirm: is the median sponsored-poll SE on the AN-109 subset different from the AN-108 universe (2.49 pp)? If the subset is systematically higher- or lower-n, the +15 pp excess generalizes differently. Suggested script:
an-NNN-an109-sample-vs-an108-universe.pyWithin-protocol multiple-test framing — which candidate fails? (puzzle / extension): at protocol level, AN-109 flags "did any candidate fail." Decompose: for sponsored protocols that failed, is the failing candidate disproportionately the sponsor's? If yes, the tail-detection signal is targeted at the sponsor's candidate and is genuine bias. If random, the excess detection is residual noise, not bias-driven. Suggested script:
an-NNN-which-candidate-fails-the-blind-audit.pyRegulatory framing — calibrated detection threshold (blind spot): AN-109 is mechanism evidence, not a policy tool. A practically usable blind audit would need (i) an empirical-DEFF-calibrated z-threshold, (ii) a baseline rate from non-sponsored polls in the same regulatory window, and (iii) an excess-detection-rate alarm rather than a per-poll alarm. Note: a TSE auditor would also have access to the sponsor field, so "blind" is somewhat artificial — the relevant scenario is more like a journalist or third-party methodologist auditing the registry. Writing item for §sec:policy.