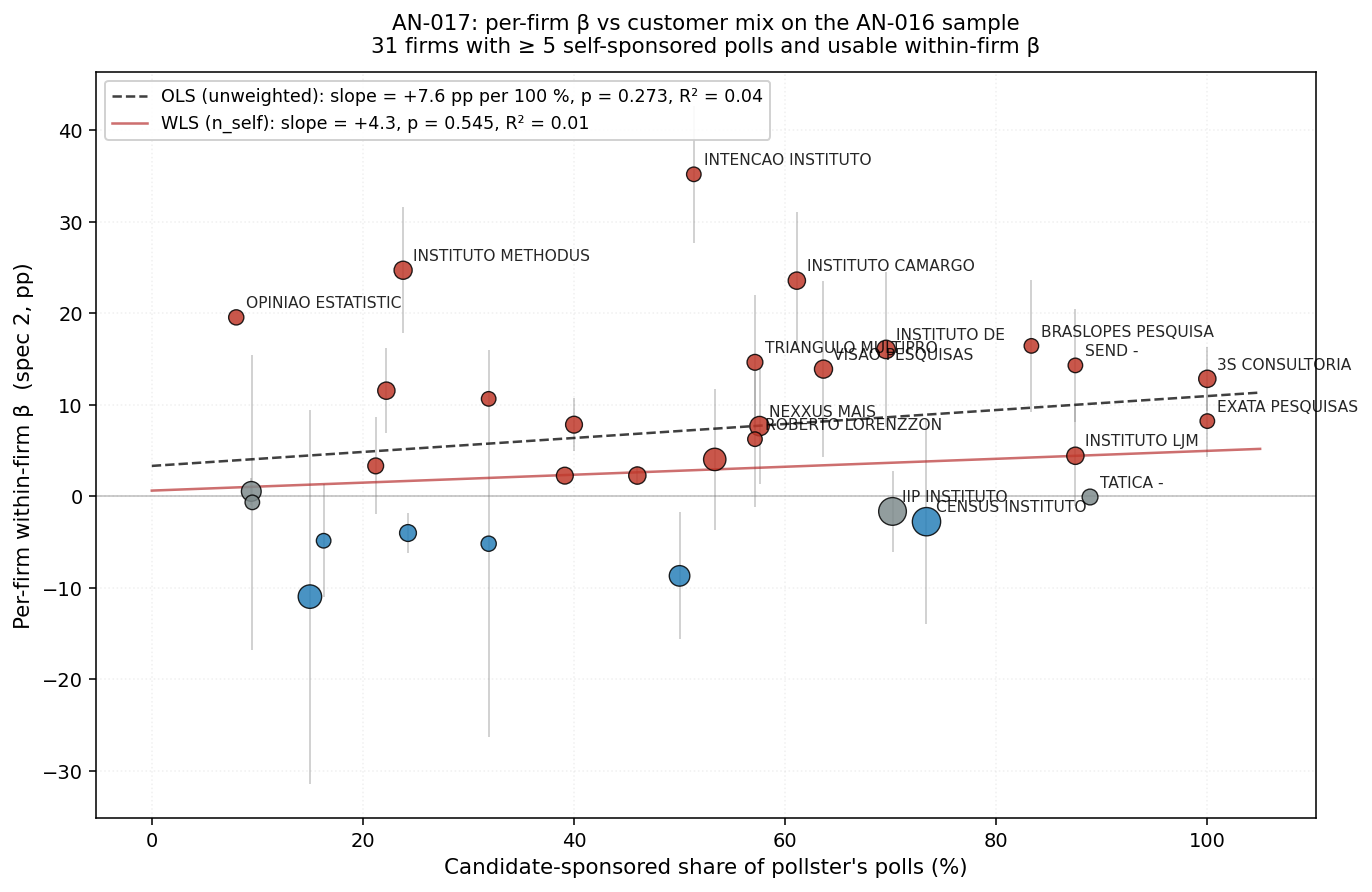
Customer-mix sorting prediction holds in *sign* but **does not sharpen** with the 3× sample. AN-007's 11-institute slope (γ=+13.6, p=0.40, R²=0.08 unweighted) drops on the AN-016 31-firm sample to γ=+7.6 (SE 6.8, p=0.27, R²=0.04 unweighted) / γ=+4.3 (SE 7.1, p=0.54 WLS). The pollster_self share has γ=−19.9 (p=0.10, marginal) — firms that mostly do their own marketing polls slant less for sponsors, the right direction. But candidate-share alone explains < 5% of the cross-firm β variance, so AN-016's striking 46-pp dispersion is NOT primarily a customer-mix story. The pattern (big firms low β, small firms high β) likely needs a firm-size / volume / age explanation that customer-share-alone misses — parked as the AN-018 follow-up.
Question
AN-007 estimated a per-pollster β-on-candidate-share slope on 11 institutes and found the predicted positive sign but with wide confidence intervals (γ = +13.6 pp per 100% candidate share, p = 0.40, R² = 0.08). The sample was thin because the per-pollster β estimates from heterogeneity.py required non-degenerate cluster-robust SEs — many firms with ≥ 5 self-sponsored polls were dropped.
AN-016 estimates per-firm β using a different spec (within-firm spec 2 with candidate FE + methodology controls, race-FE fallback) and produces 31 firms with usable β across the ≥ 5 cut. The substantive finding from AN-016 — big-name firms near zero, niche firms heavily positive — predicts the AN-007 slope should be sharper on the larger sample.
Design
source/analysis/an-017-customer-mix-refresh.py:
- Reads the AN-016 per-firm β table (31 firms).
- Computes per-institute customer-mix shares from the sponsor parquet
using AN-007's
classify_sponsor/classify_polllogic at the protocol level. - Regresses β on
share_candidate(unweighted OLS and n_self-weighted WLS), and a secondary spec withshare_media_onlyandshare_pollster_self_onlyas separate regressors. - Tabulates the slope, SE, p, R², and n alongside AN-007's 11-institute numbers for direct comparison.
- Scatter plot with regression line, point area ∝ n_self.
Results
Sample
| Source | n firms | candidate-share | β |
|---|---|---|---|
| AN-007 (11 institutes, heterogeneity.py β) | 11 | mean 0.28, range [0.02, 0.69] | mean +5.7, range [−18, +30] |
| AN-017 (31 firms, AN-016 within-firm spec-2 β) | 31 | mean 0.50, range [0.08, 1.00] | mean +7.2, range [−11, +35] |
Notable: AN-016's sample skews more toward candidate-heavy firms (mean candidate-share 0.50 vs AN-007's 0.28) because the within-firm spec needs ≥ 5 self-sponsored polls per firm, biasing toward firms that do sponsor work. The 31-firm panel is substantively a different cohort than AN-007's, not just a 3× expansion of the same one.
Primary regression
| Spec | γ (candidate-share) | SE | p | R² | n |
|---|---|---|---|---|---|
| AN-007 unweighted | +13.58 | 15.39 | 0.40 | 0.08 | 11 |
| AN-007 WLS (n_self) | +6.28 | 8.34 | 0.47 | 0.06 | 11 |
| AN-017 unweighted | +7.63 | 6.83 | 0.27 | 0.04 | 31 |
| AN-017 WLS (n_self) | +4.34 | 7.09 | 0.54 | 0.01 | 31 |
Slope direction is right (+) in all four cases. The 3× sample tightens the SE roughly by half (15.4 → 6.8 unweighted), but the point estimate also drops by half (+13.6 → +7.6) — so the p-value only modestly improves (0.40 → 0.27). The relationship is suggestive but not significant at conventional levels.
Secondary regression
β ~ α + γ_m · share_media + γ_p · share_pollster_self:
| Coefficient | γ | SE | p |
|---|---|---|---|
| share_media | −6.19 | 8.48 | 0.47 |
| share_pollster_self | −19.87 | 11.78 | 0.10 |
R² = 0.10, n = 31. The pollster_self coefficient is borderline significant with the predicted negative sign: firms whose business is mostly their own marketing polls (rather than candidate or media-sold polls) slant less when they do take a sponsor job. Interpretation: a firm that survives by self-publishing reputation- managed polls cannot risk visible client-slant. The candidate-share and media-share coefficients are both close to noise.
Interpretation
The customer-mix sorting prediction (from docs/theory.md § "Pollster
reputation and customer-mix sorting") holds in direction but not
in magnitude / significance. AN-016's striking finding —
big firms (CENSUS, IIP, Paraná, Verita) near β ≈ 0; smaller firms at
β = +15 to +35 — is not primarily explained by candidate-share
of customer mix. R² < 0.05 on the linear specification, and the
WLS slope is essentially zero (+4.3, p = 0.54).
Two alternative explanations for the AN-016 dispersion that AN-017 does not rule out:
- Firm size / volume as discipline. Big firms face larger absolute reputation cost from a public miss, regardless of customer mix. A firm with 1,500 polls under its name across 2024 (Paraná) loses more reputation from one bad sponsored poll than a firm with 200 polls (Methodus). The customer-share variable doesn't capture firm size; firm size might be the load- bearing axis. Parked as the AN-018 follow-up — regress β on log(n_total) or test β by firm-size tertile.
- Selection of sponsors into firms. Candidates who want slant choose firms known to deliver it. The cross-firm β dispersion reflects which firms accept which jobs, not how firms behave given a job. Customer-share would not pick this up cleanly because both slant-friendly firms and slant-averse firms have similar candidate-share if both serve a mix of clients with different demand for slant.
The pollster_self coefficient (−19.9, p = 0.10) is the most substantively interpretable single result: firms that mostly publish their own marketing polls (where their public reputation is the direct product) discipline themselves more on sponsored work. Worth mentioning in the paper note's mechanism section as suggestive evidence for the reputation-sorting story, even though the headline candidate-share slope is too noisy.
Follow-ups
- Firm-size discipline test (AN-018) (highest paper-value extension). The AN-016 cross-firm β heterogeneity is striking but not explained by customer-mix. The most natural alternative: firm size / volume as reputation-discipline. Regress per-firm β on log(n_total_polls); split β by firm-size tertile. If a clean monotone relationship exists, the implied policy reading shifts to "big firms self-discipline; the bias problem lives in small firms" — sharper and more actionable than the customer-mix story.
- Cite both AN-007 and AN-017 in
theory.md(blind spot). The "Pollster reputation and customer-mix sorting" section indocs/theory.mdcurrently cites only AN-007. Add a one-line update: "AN-017 refreshes the slope on 31 firms; γ = +7.6 (unweighted) / +4.3 (WLS), with R² < 0.05. The customer-mix prediction holds in sign but is not statistically significant on the expanded sample. The pollster_self coefficient (γ = −19.9, p = 0.10) is the strongest single signal." - Update paper note's industry-segmentation framing (refinement of the AN-016 lead). The original "customer-mix sorting" framing for the AN-016 dispersion is not fully supported by AN-017. The paper note should acknowledge the AN-016 dispersion as the substantive empirical finding while pivoting the mechanistic explanation toward firm size (pending AN-018). Until AN-018 lands, the safe framing is descriptive: "the industry is segmented; the headline +7.85 is a cross-firm average, with big-name firms near zero and niche firms heavily positive — see AN-016 forest plot."