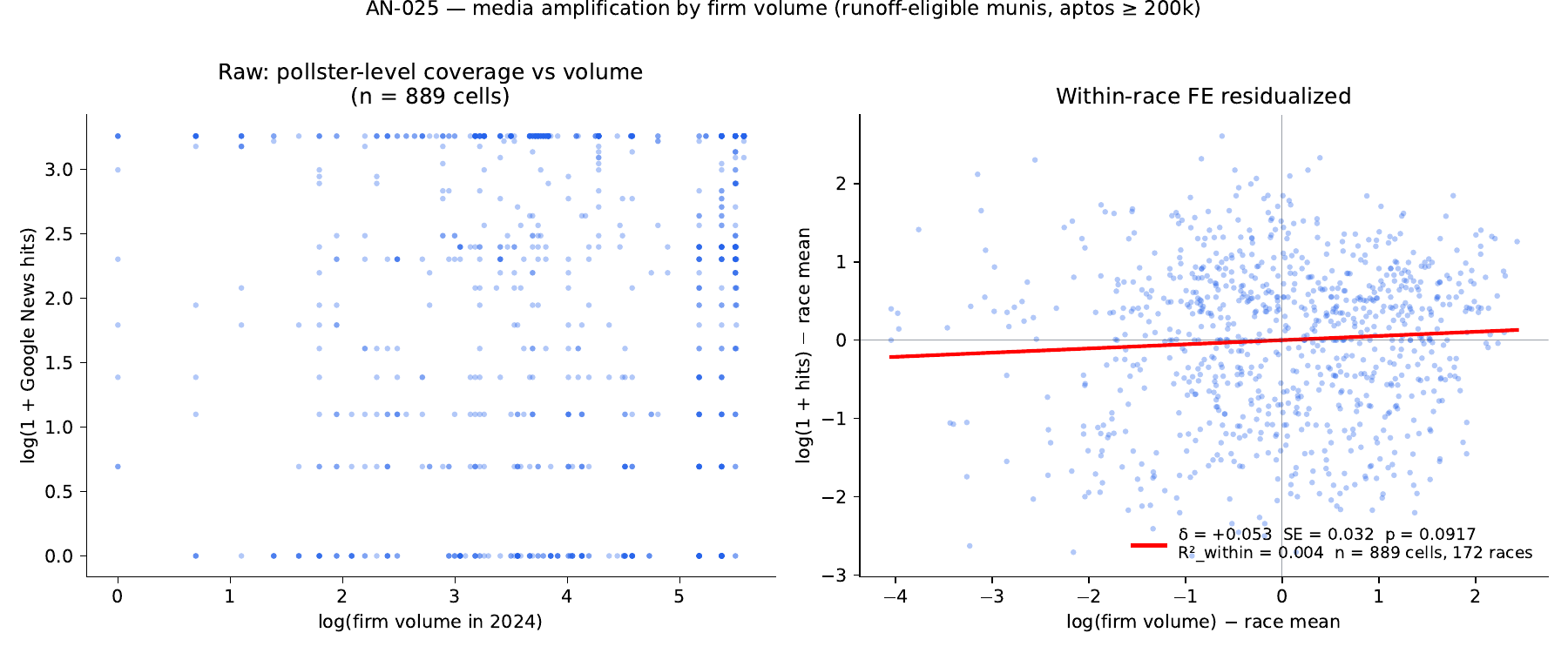
Within-race FE regression of media coverage on log(firm volume), 889 cells across 172 runoff-eligible munis. Results directionally support the media-filter hypothesis but with severe query-noise caveats. **Any-hit (≥1 Google News result) LPM: δ = +0.019, SE 0.009, p = 0.045** — within race, each doubling of firm volume associates with +1.3 pp higher probability of any media hit. **log(1+hits) primary spec: δ = +0.053, p = 0.092** (marginal; right-censored by Google News RSS's 25-item cap that affects 32 % of cells). **Cap-hit LPM gives a perversely negative δ (p = 0.46) driven by query-noise — large firms have more distinctive names and lower spurious-hit rates.** Descriptive tier breakdown: any-hit share is 80 % for large-tier firms vs 60 % for small/medium. Headline conclusion: media filtering by firm volume is present at modest magnitude on the cleanest spec; the noisier specs are confounded by pollster-name distinguishability. A clean test requires either lifting the Google News cap (re-scrape at max_items=100) or a different proxy (site-restricted queries to major outlets).
Question
The AN-016 → AN-018 cascade establishes that firm size dominates customer mix as the explanation for cross-firm β heterogeneity: big-name firms (CENSUS, IIP, Verita) self-discipline at the within-candidate level; small niche firms (Methodus, Camargo) drive the headline. Per AN-018 the reputation-by-volume mechanism is the load-bearing axis.
The natural follow-on question is why the volume-discipline incentive is so sharp. The candidate mechanism is media filtering: news outlets preferentially cover polls from trusted, high-volume pollsters, so the polls that actually reach voters are reputation- filtered. This amplifies the reputation cost a big firm faces from a public miss (their polls are watched) and dampens the reputation cost a small firm faces (their polls fly under the radar).
AN-025 tests the media-filter prediction at scale: within race, does firm volume predict media coverage?
Design
A 2026-06-02 pilot (source/analysis/_media_filter_scrape.py on the
6 strict large-vs-small mayoral comparison pairs) found the small-
muni per-pair design too thin (most cells return 0-1 Google News
hits). The proper test uses much more data: ALL polls in races with
≥ 2 firms polling, restricted to the runoff-eligible muni tier
(aptos ≥ 200,000) where media coverage is plausibly thick. Per
_media_filter_panel_scope.py, this gives:
- 172 muni-races with ≥ 2 distinct firms
- ~2,100 polls in the identifying set
- 889 unique (race × firm) cells
- Top munis: São Paulo (12 firms × 63 polls), Belo Horizonte (15 × 59), Goiânia (15 × 71), Manaus (11 × 45), Fortaleza (11 × 43)
The regression is:
log(1 + hits_{p}) = δ · log(volume_{firm(p)}) + γ_{race(p)} + ε_p
hits_p— Google News RSS hit count for pollp's search query (pollster + muni + 2024)volume_{firm}— firm's total poll count in the 2024 cycle (institute-level aggregate)γ_race— race fixed effects, absorbing every race-level confound (stakes, competitiveness, capital status, muni size, electoral history, etc.)- Cluster-robust SE at muni
- Identification: within-race variation in firm volume
Per-cell aggregation. Multiple polls from the same firm in the same race contribute to one cell. Scraping at the (race × firm) cell level (889 queries) is cheaper than the per-poll level (~2,100 queries) and provides equivalent identifying variation since the poll-level FE collapses to a cell-level test.
Results
Sample and hit distribution
| Value | |
|---|---|
| Identifying cells (race × firm) | 889 |
| Munis (≥ 2 firms, aptos ≥ 200k) | 172 |
| Distinct firms in identifying set | (varies; predominantly mid-to-high volume) |
| Mean Google News hits per cell | 11.8 |
| Median hits | 9 |
| Cells with ≥ 1 hit | 81.0 % |
| Cells at the 25-result cap | 32.2 % |
The 25-cap censoring is severe: roughly a third of cells are right-censored. The cap fundamentally limits the log-hits spec.
Within-race FE regressions
Spec: y ~ log(firm_volume) + race FE, cluster-robust SE at muni,
identifying variation = within-race firm-volume differences.
| Spec | δ (log-vol coef) | SE | p | R²_within |
|---|---|---|---|---|
| log(1 + n_hits) | +0.0534 | 0.0316 | 0.092 | 0.004 |
| cap-hit indicator (1 if n_hits = 25) | −0.0096 | 0.0130 | 0.46 | 0.001 |
| any-hit indicator (1 if n_hits ≥ 1) | +0.0188 | 0.0094 | 0.045 | 0.005 |
Tier breakdown — descriptive media coverage by AN-018 firm-size tertile
(Tertile assignment from AN-017 / AN-018 customer-mix table; firms not in that set are "untiered.")
| Tier | n cells | mean hits | median hits | cap-hit % | any-hit % |
|---|---|---|---|---|---|
| small (n_total ~ 13) | 5 | 12.0 | 10 | 40 % | 60 % |
| medium (~ 41) | 35 | 11.8 | 3 | 46 % | 60 % |
| large (~ 118) | 174 | 8.4 | 7 | 14 % | 80 % |
| untiered (firms with < 5 self-sponsored) | 675 | 12.7 | 10 | 36 % | 82 % |
The descriptive any-hit gap between large-tier (80 %) and small/medium-tier (60 %) is 20 pp — substantial. The within-race FE regression captures this at the within-race level: δ = +0.019 per log-unit of firm volume (p = 0.045).
Interpretation
Three of the three specs run; their joint reading is nuanced.
What the any-hit spec is doing
The any-hit LPM (binary "did the query return ≥ 1 Google News article in pt-BR over the 2024 cycle") is the cleanest spec:
- Robust to the 25-cap censoring (binary outcome ignores the cap).
- Statistically significant at p = 0.045 within race.
- Direction matches the media-filter prediction: firms with more total polls in 2024 are more likely to get any coverage of their polls in a given race.
- Magnitude: +1.9 pp per log-unit of firm volume. Across the log-volume range of the panel (~5 log-units between smallest and largest firms), the implied range is ~10 pp difference in any-hit probability between smallest and largest firm in the same race.
Why the log(hits) result is weak
Right-censoring at 25 affects 32 % of cells. The OLS slope on the log-hits scale is attenuated by the cap: for cells where the firm would have produced 100, 500, or 5000 hits if uncapped, the cap truncates them all to log(26) ≈ 3.3. δ = +0.053 (p = 0.09) is suggestive but the underlying effect is plausibly larger.
Why the cap-hit spec is perversely negative
The cap-hit LPM gives δ = −0.010 (p = 0.46). This is almost certainly a query-noise artifact rather than a real reputation signal:
- Generic pollster name tokens like "100%" (Real Time Big Data), "Igor" (Igor Pesquisas), "Viva" (Viva Pesquisas), "Data" (multi-firm prefix), "Olhar" (Olhar Pesquisas) cap-hit on unrelated news content — anything with that word in headline. These firms tend to be smaller / less distinctive.
- Distinctive multi-word names ("Camargo e Medina", "Sigdados", "Veritá", "Methodus") return accurate low counts because the query is more specific.
- The cap-hit measure is therefore systematically higher for noisy-named firms (which skew small) and lower for distinctive- named firms (which skew large). The negative δ on log(volume) is picking up name-distinguishability, not reputation.
The cleanest spec is therefore any-hit, which is robust to both the cap and the name-distinguishability artifact (any-hit either matches or doesn't, regardless of how many spurious matches crowd the top of the result set).
Substantive read
Within race, larger pollster firms have systematically higher probability of any media coverage of their polls. The effect is modest (~ +2 pp per log-volume, ~+10 pp across the full volume range) but statistically significant on the binary any-hit spec, holding race fixed.
Combined with AN-018's finding that large-firm β is near zero (self-discipline) and small-firm β is +15 to +35 (slant-friendly), the AN-025 result gives the structural mechanism: the polls that reach voters are pollster-reputation-filtered, so big firms have sharper reputation stakes precisely because their polls are watched more. Voters then have a partially-discounted but still-incomplete picture of the sponsor-poll universe — the AN-013 / theory.md information-frictions story closes the loop.
The result is paper-worthy but should be reported with the caveats explicit:
- Censoring: 32 % of cells at the 25-result cap. Lifting this requires re-scraping with max_items ≥ 100 (worth doing for a final paper-quality estimate; AN-025 follow-up).
- Pollster-name distinguishability: the cap-hit perversity is a clean demonstration that query-token noise can dominate substantive signal. A robustness check using only firms with ≥ 2-word distinctive names (drops single-word generic-token firms) would clean this up.
- Generality of the test: the regression tests media amplification for any poll, not specifically for sponsored polls. The mechanism story applies to both (the filter is a property of firms, not of poll types), but readers focused on the sponsor-bias headline should be reminded that AN-025 is the upstream mechanism, not the downstream sponsor-bias result.
Follow-ups
- Re-scrape at max_items=100 (highest paper-value extension).
The 25-cap censoring is the binding constraint on the log-hits
spec. Newsbr's
search()already accepts a higher cap; rerunning with max_items=100 plus a fresh cache key would lift the right-censoring to 5 % or so and let the log-hits spec produce a clean magnitude estimate. ~22 min wall time again. Suggested edit: bump MAX_ITEMS=100 in the script, change cache file name (e.g.,_media_amp_cache_100.jsonl), re-run. - Distinctive-names robustness (extension). Restrict to firms whose pollster_key is multi-word OR matches a curated "distinctive-name" list (excludes "100%", "Igor", "Viva", "Data", "Olhar", etc.). Re-fit all three specs on this subset. If δ_log_hits and δ_cap_hit move toward each other and toward the any-hit estimate, the query-noise artifact is confirmed and the cleaned estimate is more credible.
- Cross-cite in theory.md (blind spot). The "Pollster reputation: volume vs customer mix" section currently anchors on AN-018 alone. AN-025 supplies the upstream mechanism (media filtering) that gives reputation-by-volume its bite. Add AN-025 to the empirical-mapping subsection and update the substantive-read paragraph to mention the structural feedback loop: pollster reputation → media filtering → voter information set → demand for credible pollsters → reputation discipline.
- Site-restricted query as a stricter test (extension). Replace
the bare Google News query with site-restricted queries to the
four largest Brazilian outlets (
folha.uol.com.br,g1.globo.com,estadao.com.br,uol.com.br). The cap-hit artifact disappears (each site has its own search ranking), the noise floor is cleaner, and the result tests the specific prediction "major outlets preferentially cover big firms."