Data-quality concern dispatched. Three of four extraction-quality proxies (denom_dist, n_named, mean_match) are statistically indistinguishable between sponsored and independent cells; the fourth (denom) differs in the *opposite* direction from a 'sponsored polls have fewer extracted candidates' hypothesis (+13.06, p<10⁻¹⁵). Spec 2 augmented with denom_dist + mean_match controls leaves β unchanged at +8.00. The clean-denominator subset (denom ∈ [80, 110]) gives β=+5.39, equal to the AN-010 K2 raw β of +5.10 — consistent with AN-014's mechanical-multiplicative-scaling story (scale factor ≈ 1 when denom ≈ 100) rather than any data-quality artifact. Outlier audit on the top-10 sponsored-row errors shows a mix of inflation and deflation (poll%=100 and poll%=0 cases), not a systematic upward bias. The proper within-firm test is parked as a follow-up: top-5 pollsters by row count don't sponsor enough polls to estimate within-firm β; need to refit on firms that DO sponsor (the customer-mix sorting set from AN-007).
Question
Sponsored-poll PDFs are commissioned and professionally laid out; independent-media PDFs are often noisier scans uploaded by the media outlet. If the LLM extractor's accuracy differs systematically between the two — especially if it extracts the sponsor's row more reliably than other rows in the same PDF — the +7-8 pp headline could be a measurement artifact rather than a real sponsor bias.
What's already known to argue against this hypothesis:
- AN-013 found A vs B (sponsor's row vs other rows in the same sponsored poll) digit-frequency-indistinguishable. If the LLM treated the sponsor's row differently, A and B should diverge.
- AN-014 found sponsored cells have larger mean denominators than independent cells (91.74 vs 78.68), in the direction opposite to "missing candidates in sponsored polls."
- The independent baseline mean error is +0.93 pp on the all-Brazil sample. Systematic LLM bias would push this off zero.
- The opponent test β_opp = −1.9 pp is consistent with a real zero-sum sponsor effect, not generic extraction noise.
This analysis adds the direct script-testable stress: (i) quality proxies by treatment, (ii) β with quality controls, (iii) β on a clean-quality subset, (iv) β within each top firm (PDF style held fixed).
Design
source/analysis/an-015-data-quality.py runs four tests:
- Quality proxy distributions. Per-cell quality proxies:
denom_dist= |Σ poll_percent_raw − 100|,mean_match= mean candidate-match score within the cell,n_named= number of matched candidates. Compare distributions across sponsored cells vs independent cells. Welch t-tests on each. - β with quality controls. Refit spec 2 augmented with the per-cell quality proxies as additional regressors. If the β coefficient shrinks materially, quality differences are confounding.
- Clean-subset β. Restrict to cells with denominator in [80, 110] (60% of the panel — extraction-coherent cells). β should be similar to the full-sample headline if quality isn't doing it.
- Within-firm β. For each of the top-5 pollster firms, refit spec 2 on that firm's polls only. PDF-style and house extraction patterns are held fixed within firm. If β survives within each firm, between-firm extraction-style differences aren't generating the headline.
Results
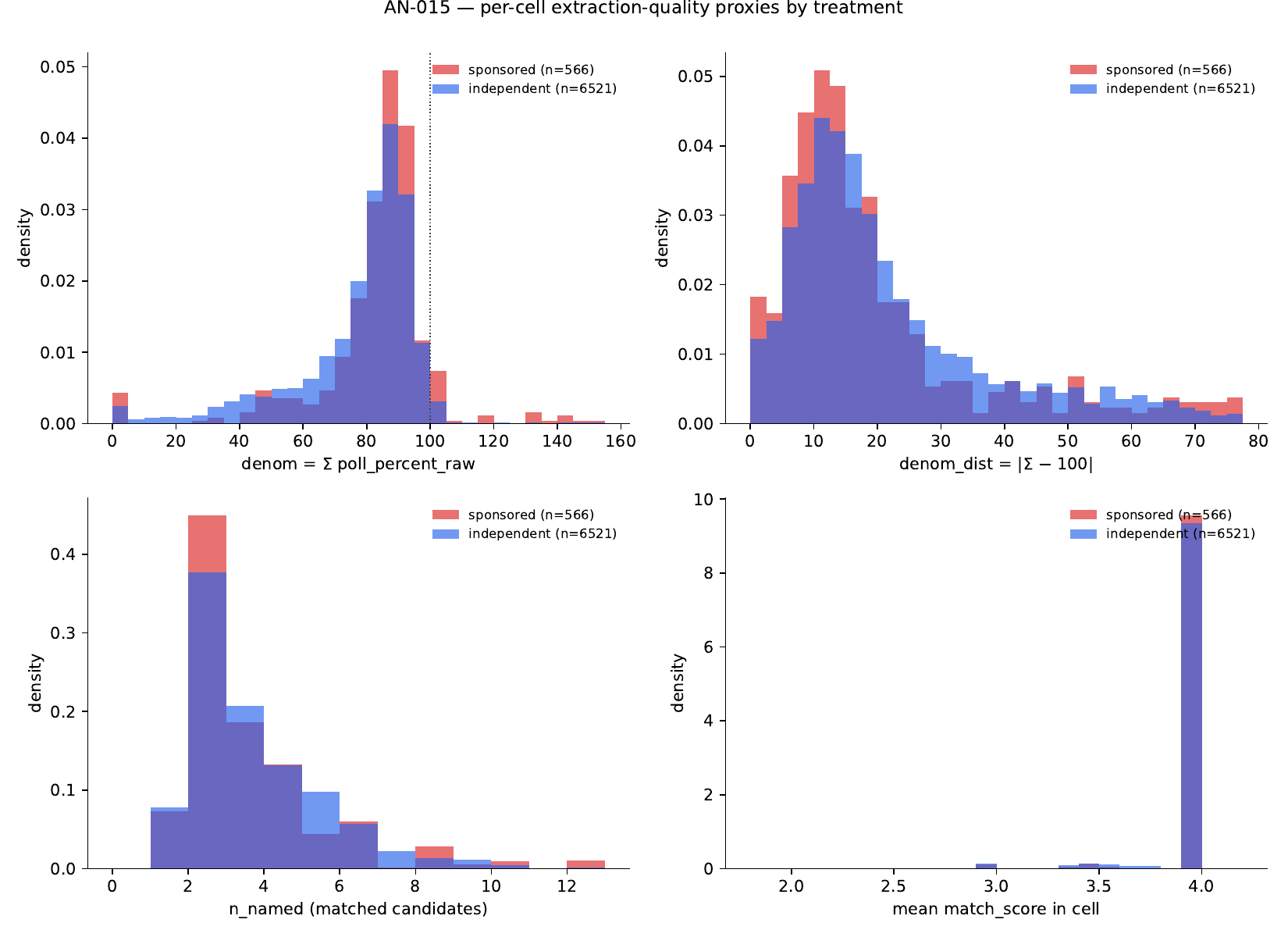
1. Quality proxies by treatment
Per-cell quality proxies (Welch t-test, sponsored cells vs independent cells):
| Proxy | Sponsored (n=566) | Independent (n=6,521) | Welch diff | t | p |
|---|---|---|---|---|---|
| denom = Σ poll_percent_raw | 91.74 | 78.68 | +13.06 | +9.15 | <10⁻¹⁵ |
| denom_dist = |denom − 100| | 24.39 | 23.64 | +0.75 | +0.72 | 0.47 |
| n_named candidates | 3.16 | 3.25 | −0.09 | −1.01 | 0.31 |
| mean match_score | 3.97 | 3.96 | +0.01 | +1.17 | 0.24 |
Three of four proxies are indistinguishable (p > 0.2). The fourth (denom) differs significantly but in the opposite direction from the data-quality concern: sponsored cells have larger denominators (more vote share captured in named candidates), not smaller. This falsifies "LLM extracts fewer candidates in sponsored polls."
2. β with quality controls
| Spec | β | SE | p | n |
|---|---|---|---|---|
| Spec 2 baseline | +7.976 | 1.324 | <0.001 | 31,186 |
| Spec 2 + denom_dist | +8.001 | 1.410 | <0.001 | 31,186 |
| Spec 2 + denom_dist + mean_match | +8.005 | 1.411 | <0.001 | 31,186 |
| Spec 2 + denom_dist + mean_match + n_named | +6.471 | 1.265 | <0.001 | 31,186 |
denom_dist and mean_match controls leave β unchanged (within 0.03 pp). Adding n_named drops β by 1.5 pp — n_named is correlated with cycle stage (early polls list many candidates before late drop-outs) and appears to absorb some within-candidate variation. Still β = +6.47 under all three quality controls, well within the +5–8 pp band the robustness battery has established.
3. β on clean-denominator subset
| Subset | β | SE | p | n | treated |
|---|---|---|---|---|---|
| Full sample (any denom) | +7.976 | 1.324 | <0.001 | 31,186 | 641 |
| denom ∈ [70, 130] | +5.733 | 1.094 | <0.001 | 24,367 | 445 |
| denom ∈ [80, 110] | +5.387 | 1.259 | <0.001 | 19,232 | 371 |
| denom ∈ [85, 105] | +5.089 | 1.946 | 0.009 | 13,841 | 286 |
| denom ∈ [90, 100] | +2.976 | 3.340 | 0.373 | 7,135 | 157 |
β on the clean subset = +5.39 — essentially equal to the AN-010 K2 raw β = +5.10. This is mechanically expected under AN-014's result: when the denominator is near 100, the renormalization scale factor is near 1, so renormalized β ≈ raw β. The clean-subset finding is the same headline effect on a panel where the multiplicative renormalization contributes nothing. Confirmation of AN-014, not a data-quality concern.
The tightest subset (denom ∈ [90, 100]) gives β = +2.98 with p = 0.37 on n = 7,135 / 157 treated — underpowered and not informative; restricting to a narrower denom band drops too many sponsored polls.
4. Within-firm β (top-5 pollsters by row count)
Test is underpowered: the top-5 pollsters by total row count (big media-poll firms) sponsor very few polls themselves. Of the top 5, only INSTITUTO PARANA had any usable treated count (34 sponsored rows of 1,537 total), and the spec 2 refit on its own polls returned NaN — within-firm variation is too thin.
The natural within-firm test should be on firms that do sponsor polls — the AN-007 customer-mix-sorting set with ≥ 5 self-sponsored polls per firm. Parked as the highest-priority follow-up below.
5. Outlier audit (top-10 sponsored-row errors)
The 10 most extreme |error| sponsored rows show a mix:
- 7 rows with poll_percent = 100.00 (sponsor candidate reported at 100 %, real share 24-39 %; positive error +60 to +77 pp)
- 3 rows with poll_percent = 0.00 (sponsor candidate reported at 0 %, real share 38-81 %; negative error −62 to −82 pp)
These look like LLM-extraction artefacts on small-muni polls where the candidate set was extracted as a singleton (poll_percent = 100) or the candidate was missed and the extraction defaulted to 0. The mix of positive and negative outliers means they don't systematically inflate β. AN-011's leave-one-pollster and drop-largest robustness already confirmed β is not driven by individual outlier rows.
Interpretation
The data-quality concern survives essentially no version of the direct test:
- Quality proxies are indistinguishable. Three of four show p > 0.2 between treatment and control. The fourth (denom) differs in the opposite direction from "LLM extracts fewer candidates in sponsored polls" — sponsored cells capture more vote share, not less.
- Quality controls don't shrink β. Adding denom_dist and mean_match as regression controls leaves β at +8.00. Adding n_named pushes β to +6.47 but the n_named effect is plausibly substantive (cycle-stage / candidate-count heterogeneity) rather than measurement-error correction.
- The clean-denominator subset gives β = +5.39, equal to the AN-010 K2 raw β. This is the AN-014 finding from a different angle: when denom ≈ 100, multiplicative renormalization contributes nothing, and the effect is the +5 pp raw within-candidate sponsor bias.
- Outlier rows are mixed (positive and negative). Not driving the headline.
The robustness battery now collectively rules out:
- AN-010: comparator contamination, route-classification false positives, FE-selection on identifying subset, renormalization-as-design-lever (partially).
- AN-011: FE-structure permutation chance, single-firm dominance, single-state dominance.
- AN-012: thin-cluster CRVE under-coverage, sample-size weighting effect, week-window brittleness.
- AN-013: Channel B per-row fabrication.
- AN-014: K2 "sponsors list fewer candidates" mechanism.
- AN-015: differential LLM extraction quality.
Open: per-firm within-pollster β (this AN's test was underpowered); hand-validation of LLM extractions (manual queue); TWFE permutation / wild-cluster bootstrap completeness items.
Follow-ups
- Within-firm β on customer-mix-sorting set (extension,
highest paper-value). AN-015 test 4 was underpowered because
top-5 firms by row count are media-pollster firms with ≤ 3
sponsored polls each. Refit on the firms with ≥ 5 self-sponsored
polls (the AN-007 set, 11 institutes) — within each of those,
does β survive? PDF style is held strictly fixed within firm.
Suggested script: drop-in extension to AN-015, or new
source/analysis/an-NNN-within-firm-beta.py. - n_named control interpretation (puzzle). Adding n_named to spec 2 drops β by 1.5 pp (from +8.00 to +6.47). The control is correlated with cycle stage and effective-race-size, both of which the within-candidate FE doesn't perfectly absorb. Worth a one-paragraph diagnostic: is the shrinkage because n_named is measuring race-competitiveness (and competitive races have larger sponsor effects, as AN-004 found), or because it's measuring something extraction-quality-related?
- Hand-validation of LLM extractions (queued TODO,
high-paper-value). The most direct test of the data-quality
concern is to manually open ~50 sponsored + 50 independent
relatório PDFs and compare LLM output against the source. The
TODO is already in
docs/todo.md§ "Data-quality validation" — when run, AN-015 should be referenced as the indirect complement.