Binomial SE on the sponsor candidate's share is ≤ 3.5 pp on 99.3 % of sponsored polls (median 2.49 pp at median n=360); +7 pp is z ≈ 2.8 against binomial SE on the median sponsored poll. Per-poll bias is statistically visible against a tight (binomial / unbiased) benchmark — informs the reputation / auditability story, not the channel decomposition. AN-110 walks this back against the empirical noise floor.
Question
The headline β ≈ +7 pp is an average over self-sponsored polls. The mechanism-distinguishing question is whether a single biased poll's +7 pp shift would be statistically visible against its own sampling SE, or buried under it.
If binomial SE on the sponsor's candidate's reported share is ≫ 7 pp on most sponsored polls, then any single poll's bias is statistically indistinguishable from noise — bias only emerges in aggregate (and a sponsor can plausibly deny each one). If SE ≪ 7 pp, each sponsored poll is a per-poll detectable outlier; the sponsor must know the poll is biased relative to the unbiased estimator at that sample size.
This bears on reputation and auditability: how visible is the bias to a sponsor's own pollster running internal sanity checks, and to an outside observer with access to a benchmark? It is silent on how the bias is produced (design tilt vs fabrication) — both can produce shifts of the same magnitude.
Design
Sample: build/assemble/cand_poll.parquet restricted to
matched_share == 1.0, finite poll_percent, and sample_size > 0.
No restriction on error.notna() — the SE doesn't require
final_share.
Per-row binomial SE: $$ \widehat{SE}_{pp} = 100 \times \sqrt{\frac{p,(1-p)}{n}}, \quad p = \frac{\text{poll_percent}}{100} $$
Three row classes:
- sponsored: rows with
sponsored_by == 1(the sponsor's candidate in a sponsored poll). - independent-of-same-candidate: rows of candidates who ever
appear with
sponsored_by == 1somewhere in the panel, wherepoll_is_independent == 1. This is the within-candidate comparator the headline regression actually uses. - other: residual rows (candidates that never appear sponsored).
Distribution stats per class: n_rows, median sample_size, median and
P25/P75 of poll_percent, median and P25/P75 of SE_pp. Plus
detectability fractions:
frac_SE_lt_7pp— fraction with SE < 7 pp (a single-poll z=1 signal would already exceed 7 pp).frac_SE_lt_3.5pp— fraction with SE < 3.5 pp (a 7 pp shift is z > 2 — the canonical "statistically significant" single-poll detection).frac_SE_lt_2.3pp— z=3 detection.
Figure: ECDF of SE_pp by row class with reference lines at 3.5 and
7 pp.
Caveat (logged, not adjusted). Binomial SE assumes simple random sampling. Brazilian muni polls use multi-stage cluster sampling with quota controls; published Brazilian methodological notes typically put DEFFs at 1.5–2.5 (random walk + sector + interviewer effects). The realized SE on the candidate share ≈ √(DEFF) × binomial SE; a DEFF of 2 inflates the binomial SE by ≈1.41×, shifting the "below 3.5 pp" fraction down. Headline calls below use binomial SE — DEFF inflation discussed in interpretation.
Results
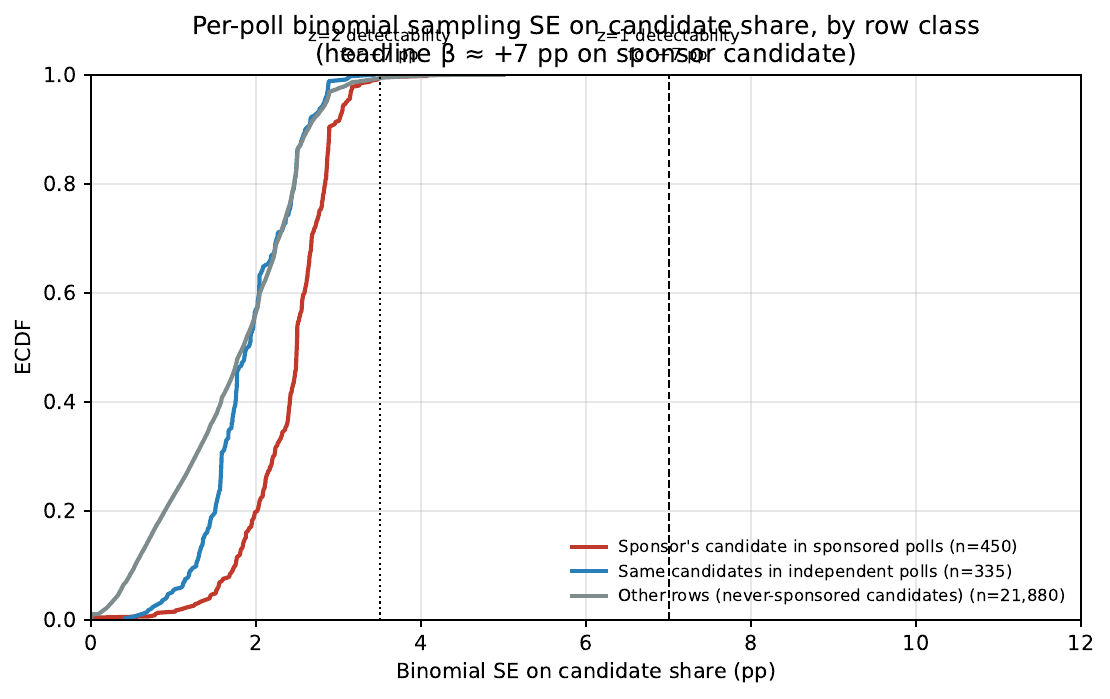
Headline sample: 22,665 cand-poll rows (matched_share==1.0, finite
poll_percent, sample_size>0). Row-class counts: 450 sponsored,
335 same-candidate independent, 21,880 other.
Per-row binomial SE on the candidate's share (table:
build/table/an-108-sampling-se-detectability.csv):
| row class | n | median n | median p | median SE_pp | P25–P75 SE_pp | frac SE<7pp | frac SE<3.5pp | frac SE<2.3pp |
|---|---|---|---|---|---|---|---|---|
| sponsored | 450 | 360 | 54.8% | 2.49 | 2.11–2.77 | 1.000 | 0.993 | 0.333 |
| indep-of-same-cand | 335 | 600 | 41.8% | 1.91 | 1.57–2.40 | 1.000 | 1.000 | 0.710 |
| other | 21,880 | 458 | 29.1% | 1.84 | 1.09–2.38 | 1.000 | 0.994 | 0.711 |
Detectability of a +7 pp shift on a single sponsored poll:
- z = 7 / 2.49 ≈ 2.81 on the median sponsored poll (binomial SE).
- 99.3% of sponsored polls have SE < 3.5 pp, i.e. a +7 pp shift would exceed z=2 on a one-sided test.
- 100% have SE < 7 pp (z>1).
Even with a Brazilian-typical design effect of DEFF=2 (multi-stage cluster + quota), realized SE ≈ √2 × 2.49 ≈ 3.5 pp on the median sponsored poll, so a +7 pp shift is still z=2.0 — statistically significant per-poll at the 5% one-sided level. Pushing to DEFF=3 (unusually high for muni polls) gives SE ≈ 4.3 pp, dropping z to ≈1.6 — borderline but still well outside "buried in noise."
Interpretation
Against a tight (binomial / unbiased) benchmark, the +7 pp bias is statistically visible on a per-poll basis. On the median sponsored poll, a +7 pp shift is z ≈ 2.8 against binomial SE — well above the canonical 1.96 cutoff. The conclusion survives DEFF inflation up to ~3.
This is informative about reputation and auditability, not about the channel decomposition (design tilt vs fabrication). A Channel A design tilt that produces a +7 pp shift would be just as visible per-poll as a Channel B fabrication that produces the same shift. The question of how the bias is generated is not addressed here; the question of whether the bias is visible to a sufficiently informed observer is.
Scope: single-hypothesis test on the known sponsor. The detectability call above assumes the observer knows which candidate is the sponsor and tests that candidate's reported share against the benchmark — a single z-statistic at α = 0.05. This is the right test for the sponsor's own pollster (or anyone who reads the contract): they know where to look, so z ≈ 2.8 on the median sponsored poll is loud. An outside auditor without sponsor information faces a different problem: they must test every candidate's reported share against its benchmark and apply a multiple-testing correction. For a 4-candidate race with Bonferroni the threshold becomes z ≈ 2.50, and combining with DEFF = 2 the +7 pp shift drops to z = 2.0 — fails the blind-audit threshold. Blind multi-candidate audit-ability is therefore a separate question addressed by AN-109. And against the empirical cross-firm noise floor — not binomial SE — the per-poll signal is much weaker: AN-110 estimates a pooled empirical DEFF* of 12.59, under which +7 pp is z ≈ 0.79. The AN-108 binomial-benchmark headline is loud only against an idealized reference.
Side observation flagged for the strategic-small-n follow-up. Sponsored polls have meaningfully smaller median n (360) than the within-candidate independent comparator (600). Even at n=360 the binomial SE is small relative to 7 pp, so the lower n doesn't rescue the noise-deniability story against a binomial benchmark. The n gap is sub-question 2 of the parent todo entry (strategic small-n for plausible deniability) and is now a partly answered probe.
Follow-ups
Strategic small-n (extension): sponsored polls have median n=360 vs 600 on the within-candidate independent side — same candidates, same races, different n. Test whether this gap is within-pair (race × week × candidate) or compositional, and check for bunching of sponsored-n just below thresholds (300, 400, 600) that yield round-number nominal CIs. This is sub-question 2 of the parent todo entry "Sampling-error envelope on biased polls" — now partially visible. Suggested script:
an-109-sponsored-n-within-pair.pyDEFF estimation from the data (extension — done as AN-110): AN-108 uses binomial SE and bounds the detectability call with rule-of-thumb DEFFs (1.5–2.5). AN-110 estimated the empirical DEFF directly from race × week × candidate cells and found pooled DEFF* = 12.59, walking back the per-poll-loud reading against the empirical noise floor.
Per-poll z-statistic distribution (extension / puzzle — done as AN-109): AN-109 ran per-poll z against the LOO independent benchmark with single-hypothesis / Bonferroni / Holm thresholds and a DEFF sensitivity panel. v2 at empirical DEFF* = 12.59 found sponsored protocols catch at 2.6× the independent baseline.